麦吉尔大学团队 投稿
量子位 | 公众号 QbitAI
当前的数据合成技术存在一定局限,主要体现在合理性与分布一致性上有所欠缺,并且缺少自动调整以适应不同数据的能力,导致其扩展性不强。
大语言模型在采样效率方面存在局限,同时上下文窗口的大小也对其产生了影响,因此它难以直接合成大规模的数据集。
如何构建出结构匹配、数据统计可靠、语义逻辑通顺的信息,这一问题迫切需要得到解决。
为此,麦吉尔大学团队提出了新方法LLMSynthor
运用此途径,我们能够将大型模型转变为具有结构感知能力的模拟器,专门用于在隐私保护需求高、数据资源匮乏的环境下,生成既保密又优质的可替代数据。

LLMSynthor:让LLM变成“结构感知的生成器”
在众多应用场景如人口统计、电子商务、出行服务等领域,数据共享面临敏感性问题,且不同类型的数据格式需要分别定制模型,这不仅导致成本上升,还影响了数据的迁移效率。
传统的建模方法,比如贝叶斯网络和生成对抗网络(GAN),往往在处理高维依赖关系时遇到困难,同时它们的泛化能力不足且稳定性较差,甚至常常产出诸如“9岁博士”这样的样本,虽然从统计数据上看是合理的,但从语义角度来看却是荒谬的。
近期,大模型同样被应用于数据生成领域,然而,它面临着诸如采样速度慢、数据分布难以控制以及上下文应用受限等问题,这些问题使得其难以高效地生成结构完整的大规模数据集。
LLMSynthor的解决方案是:它让语言模型不直接生成数据,而是转变为一种“结构感知的生成器”,并且通过统计对齐和反馈机制,不断进行迭代和优化。
整体框架如下:
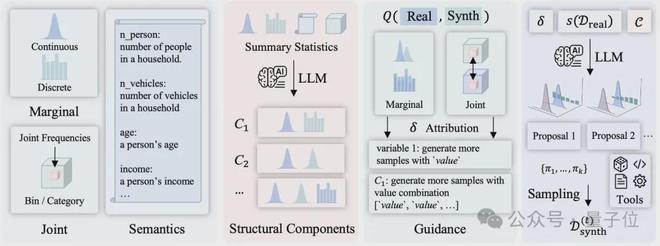
Step 1:结构推理
生成可信数据,关键是理解变量之间的依赖结构。
尽管传统的Copula模型能够将变量分布与关系模型进行分离,但在面对高维和多语义的复杂场景时,其扩展性却显得不足。
LLMSynthor的核心创新之处在于:通过运用大型语言模型来模仿Copula的功能。
LLM可以被看作是现实世界中联合分布的高维先验,其预训练阶段已经将人类行为和社会结构的变量共现规律融入其中。
通过对统计摘要(包括频率、分布等)的深入理解,它能够揭示变量之间更为复杂的关联,同时,还能借助语义信息来发掘其中的潜在依赖关系。
Step 2:统计对齐
LLMSynthor并非直接对照原始数据,它采取的方式是,通过计算统计数据,例如变量分布、联合频率等,来评估实际数据与生成数据之间的差异程度。
这样,就既保留了结构信息,又避免泄露个体数据。
即便输入的是汇总的指标,仅凭统计特性亦能产出结构完善且语义统一的模拟数据,这种数据特别适用于人口普查、问卷调查等对隐私保护要求较高的场合。
此外,LLMSynthor的校准机制具有可追溯性,它不仅评估了“整体的偏差程度”,而且能够精确指出这些偏差是由哪些特定变量或变量组合所引起的。
这种细致入微的反馈可以直接应用于下一轮的生成结构调整,从而实现逐步的调整与对齐。
Step 3:生成分布而不是样本
传统方法逐条生成样本,效率低且难控分布。
LLMSynthor被调整为输出一系列可供采样的规则(即提议),例如:“一位25岁的女性,身处一线城市,正在购买化妆品”,随后进行大规模的采样操作。此外,该系统还具备调用图像等外部生成器的能力,从而拓展至多模态任务的执行。
该建议在统计反馈与LLM常识的双重指导下,能够自然地规避诸如“10岁博士”这类不合理的变量搭配。
此方法不仅运作效率高、架构稳固可靠,而且能够借助“分布式描述性语言”手段,促使不同模型实现协同作业,进而达成跨模态、多来源、多目标的数据合成与仿真。
Step 4:迭代对齐
经过反复运用“结构推断、数据统计、规则构建以及新数据采集”这一流程,模型最终能够构建出一个在结构上和统计上均与实际数据高度相似,同时合乎常理的合成数据集。

理论保障
除了经验效果,LLMSynthor还具备理论收敛保障。
LLMSynthor团队提出了局部结构一致性定理,即:在合理的假设条件下,对于某个变量或变量组的分布,若其初始存在一定的偏差,通过有限的迭代过程,可以将误差控制在一个可接受的范围内。
这表明LLMSynthor并非仅仅是“随心所欲地接近”,而是通过数学的保证,逐步向真实的数据结构靠拢。
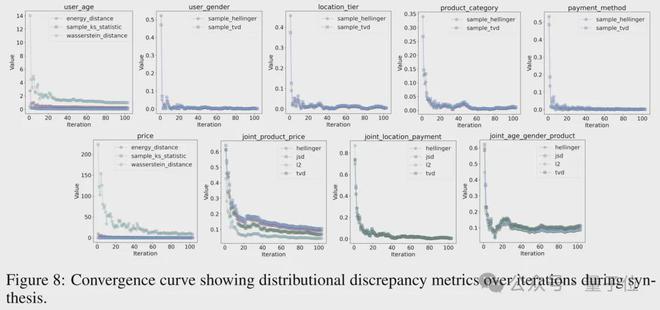
多场景实测
为了检验LLMSynthor的实际应用效果和系统稳定性,研究者选取了电商交易、人口统计以及城市出行等三个具有典型性的实际场景进行了实证研究。
电商交易生成
这是一个包含连续与离散变量的混合场景,变量关系复杂。
作者依托贝叶斯网络技术,构建了具有明确结构的可控数据集,旨在对建模能力进行评估。
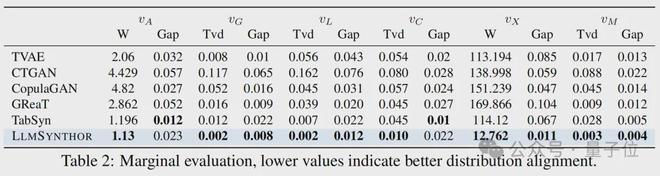
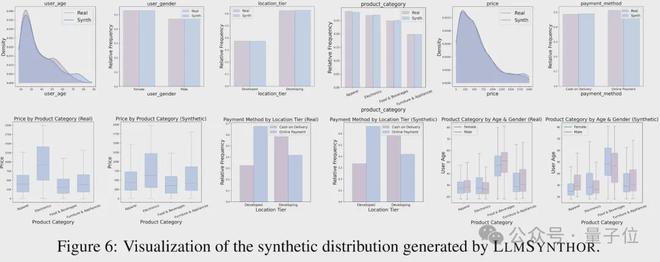
结果显示,LLMSynthor在边缘分布误差和联合分布误差两方面均展现出卓越性能,能够精确地复现变量之间的依赖关系。
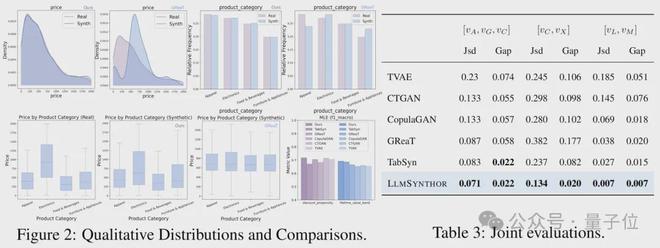
进一步的实验预测表明,该模型在真实数据集上的表现最为出色,其训练所用的合成数据展现出极高的实用价值。
人口微观合成
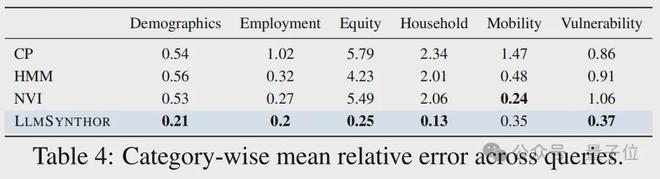
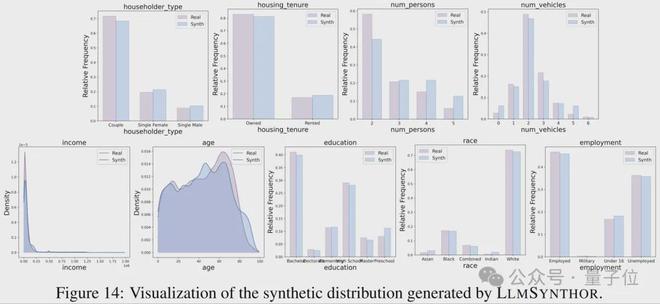
人口数据中,家庭与个人层层嵌套,其结构天然呈现非结构化特征。此类数据在诸如城市规划、政策评估以及资源配置等众多关键领域得到广泛应用。LMSynthor具备处理这种复杂结构的能力,并且在包括老年贫困率在内的16项政策指标中,相较于现有方法,表现出了显著的优越性。
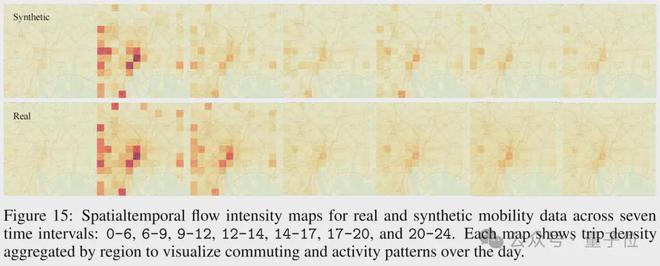
城市出行模拟
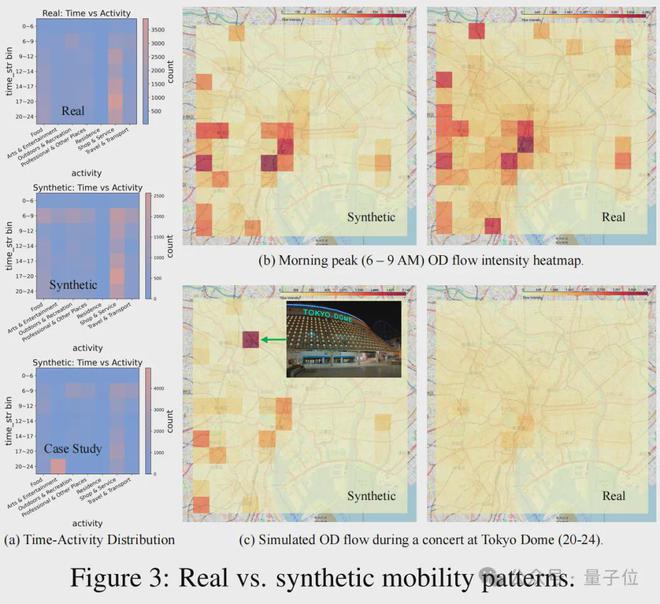
出行信息涵盖了时间序列、地理位置以及行为模式等多种繁杂类别,这些信息构成了交通模拟和紧急情况应对的基石。
LLMSynthor依托于多渠道数据,有效地生成了与都市生活步调相契合的模拟路径。尤为重要的是,该系统能够对提示信息做出反应,进而控制生成过程。
例如,当东京巨蛋于晚上8点举办演唱会时,合成数据便会揭示该时段的客流波动情况,同时显示出其强大的现实再现能力和场景控制技巧,这些特性使其非常适合用于政策模拟和活动预演。
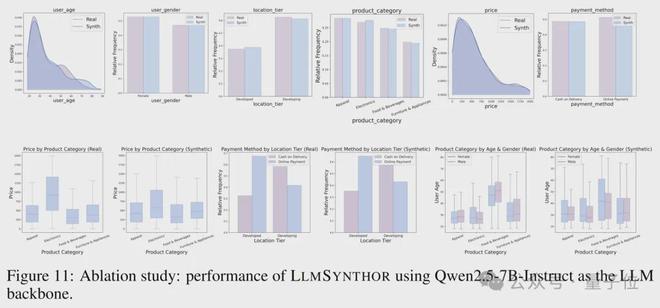
大模型兼容情况
LLMSynthor在生成方面表现出色,无需经过训练,并且能够与多种大型模型相兼容。即便更换为Qwen-2.5-7B等开源模型,也能保持稳定运行。此外,它还拥有出色的扩展性和良好的实际应用适配能力。
本篇论文的地址为:https://arxiv.org/pdf/2505.14752,该链接指向了该研究的详细内容。
