你以为,AI推理的速度已经够快了?
不,英伟达再次展现了其颠覆性的实力——就在不久前,他们凭借Blackwell实现了AI推理领域的又一突破,刷新了新的记录。

仅凭单节点配置(含8颗Blackwell GPU)的DGX B200服务器,英伟达便取得了Llama 4 Maverick模型每秒为单个用户生成1000个token(每用户每秒生成token数)的卓越性能!

单节点使用8块B200 GPU
该速度纪录是通过AI基准测试服务Artificial Analysis进行独立测量的。
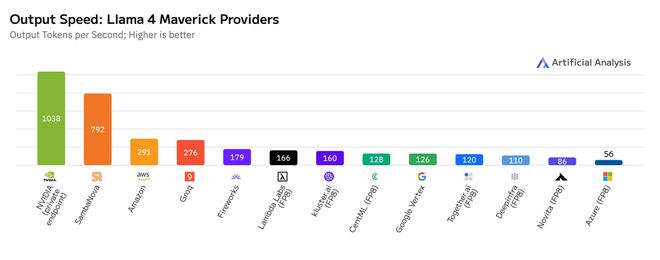
而且,更让人惊叹的是,这款名为GB200 NVL72的服务器,它搭载了72颗Blackwell GPU,其整体吞吐量竟然高达72,000 TPS!

GB200 NVL72液冷机架原型机
这场速度革命的幕后,是一整套精心布局的技术组合拳——
因此,Blackwell的性能潜能得到了全面释放,成功实现了速度提升至四倍,一举超越了之前的最强Blackwell基准版本!
迄今测试过最快Maverick实现
这次优化措施在保持响应准确度的同时,显著提升了模型性能。
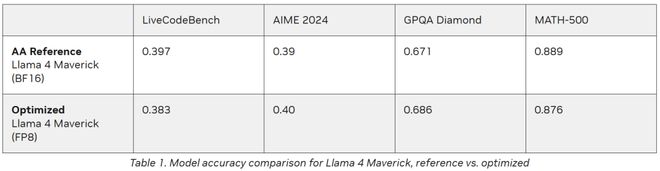
英伟达在GEMM(通用矩阵乘法)、MoE(混合专家模型)以及Attention(注意力)运算中采用了FP8数据类型,这一举措旨在缩小模型规模,同时充分挖掘Blackwell Tensor Core技术所提供的FP8高吞吐量优势。
根据表格中的数据,运用FP8数据格式后,该模型在多个评估指标上的精确度与Artificial Analysis使用BF16数据格式进行测试所获得的精确度相当。
为何减少延迟至关重要?
在众多应用生成式AI的场合,我们通常需要在处理速度与响应时间之间寻求一个恰当的平衡,以确保众多用户在同时使用时,能够享受到相对满意的体验。
然而,在诸如需迅速作出关键抉择的场合,「反应速度」显得尤为关键,即便是微小的延误也可能引发严重后果。
不论您追求的是高效处理大量请求,抑或是期望在处理众多请求的同时保持快速响应,亦或是只希望为单个用户提供最短的服务延迟,Blackwell的硬件均能成为您的不二之选。
图中展示了英伟达在推理阶段所采用的内核优化与集成策略(红色虚线框进行了标注)。
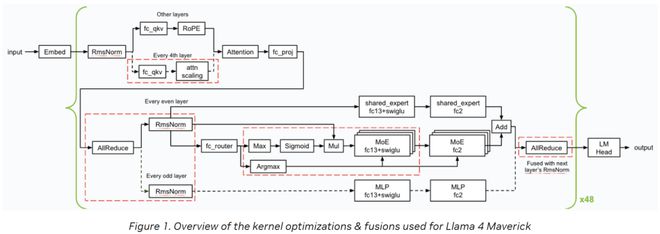
英伟达成功研发了多款低延迟的GEMM内核,同时引入了多种内核融合技术(包括FC13与SwiGLU的融合、FC_QKV与attn_scaling的结合,以及AllReduce与RMSnorm的整合),这使得Blackwell GPU在极低延迟的应用场景中展现出卓越的性能。
CUDA内核优化与融合
在内核优化与融合方面,英伟达采用了以下几项关键技术:
通过采用空间分割技术(亦称warp专业化)以及精心设计的GEMM核心,我们能够以高效率从内存中提取数据,进而充分利用NVIDIA DGX所拥有的庞大内存带宽——高达64TB/s。
将GEMM权重以一种优化的swizzled格式进行重排。
通过使用Blackwell第五代Tensor Core进行矩阵乘法运算,并确保在从Tensor内存中提取运算结果时,能够享受到更加优化的数据排列方式。
通过对K和V张量序列长度的维度进行计算划分,对Attention的核心功能进行了性能优化,从而使得计算工作可以在多个CUDA线程块之间实现并行处理。
此外,通过采用分布式共享内存技术,实现了同一线程块集群内不同线程块间的结果汇总工作的高效执行,进而减少了访问全局内存的必要性。
通过运用不同运算方式间的整合,有效降低核心执行过程中的消耗,并减少对内存进行加载和存储的频率。
将AllReduce计算与紧随其后的RMSNorm计算以及量化处理合并为一个单一的CUDA内核,同时,也将SwiGLU计算与它前面的GEMM计算整合在一起。
程序化依赖启动(PDL)
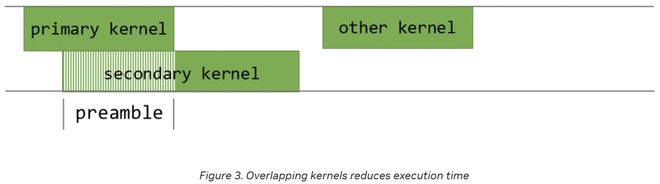
程序化依赖启动(PDL)是CUDA的一项特性,此功能旨在缩短同一CUDA流中连续两个CUDA内核执行时GPU的闲置时长,并且还能实现这两个内核的局部并行执行。
在默认设置下,若多个内核需在同一CUDA流中启动,则后续内核需在先前内核完成执行之后方能启动。
这种机制会导致两个主要的性能问题:

借助CUDA平台中的程序化依赖启动接口,英伟达得以实现次级内核的启动,即便主内核仍在持续运行。这种机制使得次级内核可以在主内核活动期间提前启动执行。
在预备阶段,次级内核能够执行与主内核执行无关的计算任务,同时进行相关数据的加载。
这不仅消除了两个相邻核心间的执行空档,同时大幅提高了GPU的效能;因为当主导核心仅占用GPU中的一部分流多处理器(SM)时,那些未被使用的SM便可以启动次级核心的运行。
推测解码
推测解码技术颇受青睐,它能够在不降低文本生成质量的基础上,有效提升大型语言模型的推理速度。
这项技术运用一个体积更小、运行速度更快的“草稿”模型来预判一系列推测的token序列,随后,更大规模(通常也更为缓慢)的LLM将并行对这些token进行核实。
其加速效能源自于:在目标模型进行单次迭代的过程中,能够产生多个token,然而,这也意味着草稿模型会带来一些额外的成本。
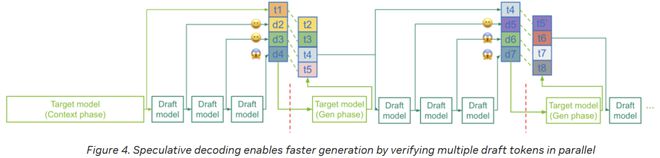
端到端的工作流
在目标模型完成上下文构建阶段——该阶段同样会产出token t1——紧接着,草稿模型便迅速地生成了一系列可能的token,诸如d2至d4。
随后,目标模型便步入生成环节,该环节中,模型将对整个草稿序列进行逐一检查,同时,对每个位置的后续token进行一次性并行确认(或创建)。
如图所示,一旦草稿中的token与目标模型即将输出的token相吻合,目标模型就有可能采纳其中的一些token(例如d2、d3),而与此同时,则会摒弃其他token(例如d4)。
该过程持续循环:一旦某个token被采纳,它便会被保留;若遇到拒绝情况(如d4遭到拒绝),目标模型将提供正确的后续token(例如t4);随后,草稿模型将生成一个全新的预测序列(比如d5至d7)。
系统通过同时验证多个token——而非依赖速度较慢的目标模型逐一生成——同时充分利用草稿模型的快速推断功能,从而实现了速度的显著提升,尤其是在草稿模型的预测准确性较高的情况下。
“接受长度(AL)”这一概念指的是,在单个验证流程中,平均能够有效产出的token的数量。
AL值越高,加速效果越显著。
针对这一问题,英伟达选择了EAGLE3架构作为其推测解码策略,该策略主要通过调整推测层中前馈网络(FFN)的规模,以实现对接受长度(AL)的优化。
在推理阶段,我们必须对目标模型进行前向传播,并在此过程中,细致地记录下不同层级——包括初始层、中间层以及末端解码层——所输出的隐藏状态,这些状态分别对应于低、中、高三个特征级别。
随后,我们将这些不易察觉的状态与token的嵌入进行融合,并将所得结果导入推测层。该推测层进而采用自回归模式,生成一份草稿token序列,以便目标模型进行并行化的验证。
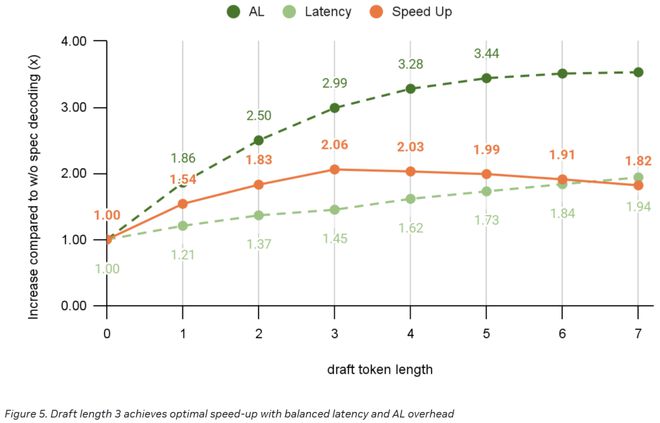
推测阶段的成本虽然不高,但仍不容小觑。因此,我们面临的核心问题是在草稿长度和端到端加速效果之间找到一个最佳的平衡点。
草稿越长,AL值通常也越高,然而,这也意味着运行草稿模型所带来的额外开销会随之上升。在英伟达进行的实验中,我们发现,当草稿长度设定为3时,能够实现最佳的加速效果。
通过CUDA Graph和重叠调度器减少主机端开销
推测解码过程中,另一个难题在于如何降低主模型与草稿模型间通信及同步所产生的大量成本。
若英伟达将采样或验证的机制部署在主机端,那么将在主机与设备之间增加额外的同步环节,这可能会对CUDA Graph的完整性造成损害。
因此,英伟达决定将验证机制留在设备内部,这样便可以将目标模型的前向传播过程、验证机制以及草稿模型的前向传播操作,全部融合进一个统一的CUDA Graph中。
此外,英伟达推出了TensorRT-LLM的叠加调度机制,旨在使当前模型的正向传播与后续迭代的前向传播准备以及CUDA Graph的启动阶段能够同步进行。
使用torch.compile()优化草稿模型层
验证逻辑在设备端是通过Torch的原始操作来执行的,这一做法使得英伟达设备上产生了众多微小的Torch原生内核。
手动融合这些内核不仅复杂,且容易出错。
因此,英伟达选择了torch.compile()这一工具,利用OpenAI Triton的功能,自动实现了内核的整合,并生成了性能最卓越的版本。
该措施使得英伟达成功将草稿模型的成本从25%大幅削减至18%,尤其是在草稿长度为3的情况下。
总结
总体而言,这一创纪录的速度得益于Blackwell架构的强大性能,自CUDA底层至应用层级的深度软件优化,以及英伟达专门定制的推测解码技术的显著提升。这三者的完美结合,正是对下一代AI交互应用对低延迟需求的直接回应。
正如英伟达所呈现的,这些技术革新确保了即便面对超大规模模型,也能保证其具备充足的运算速度和响应效率,进而支撑起流畅的实时用户交互体验以及复杂人工智能实体的部署需求。
作者介绍
Yilin Fan

尹林帆担任英伟达公司的高级深度学习工程师职位,他的主要工作领域集中在TensorRT及其子模块TensorRT-LLM的性能优化上。
他持有卡内基梅隆大学颁发的软件工程硕士学位,同时具备北京航空航天大学的学士学位。
在加盟英伟达之前,他曾在小马智行供职,主要负责对自动驾驶汽车上的深度学习模型进行优化和实施部署。
Po-Han Huang

Po-Han Huang是英伟达的深度学习软件工程师。
在过去的六年多里,他始终专注于运用TensorRT与CUDA技术进行优化,以此目的在于提升已训练深度神经网络模型的推理速度。
他持有伊利诺伊大学厄巴纳-香槟分校颁发的电子与计算机工程领域的硕士学位,其专业知识广泛,包括但不限于深度学习加速技术、计算机视觉处理以及GPU架构设计。
Ben Hamm

本·哈姆担任英伟达的技术产品经理一职,他的主要工作领域集中在提升和优化大型语言模型的推理性能。
在此之前,他曾在亚马逊公司担任产品经理一职,主要负责Alexa语音助手的唤醒词检测机器学习框架。此后,他加入了OctoAI,继续担任LLM托管服务的项目经理。随着OctoAI公司被收购,他也随之转到了英伟达公司工作。
有趣的是,他身为一位对计算机视觉充满热情的爱好者,竟然还自主设计并创造了一款由人工智能技术驱动的智能猫门。
参考资料:
NVIDIA的Blackwell芯片凭借metas Llama 4和Maverick技术,成功突破了每秒1000次交易的用户门槛。
