为什么AI一定要走到终端?
一句话总结:用户需求逼着AI“下沉”。
设想一下,当我们使用扫地机器人、穿戴式设备或是安防摄像头时,我们都期望这些设备能够自主作出判断,无需每次都将数据上传至云端等待反馈。这样做不仅效率低下,而且可能触及个人隐私及网络稳定性的问题。
依据Gartner的统计,AI芯片行业在2019年达到了120亿美元的规模,预计到2024年将增至430亿美元。这其中,边缘AI的发展成为了一个关键推动力。
然而,将人工智能技术部署于体积小巧的嵌入式设备上,面临的最大难题可概括为“限制”二字。这包括功耗的限制、算力的限制、内存的限制等诸多方面。传统的微控制器(MCU)根本无法支撑复杂的神经网络模型。若强行加入一个图形处理单元(GPU),则会导致整个系统的成本和功耗攀升至难以承受的程度。
因此,“低功耗的AI专用微控制器”成为了实现边缘智能的关键途径。然而,无论如何,只有当边缘人工智能技术能够在所有嵌入式系统中便捷地获取和应用时,它才能实现全面普及。
在此情境下,MCU市场的领军企业们已不再满足于仅仅在软件工具包中添加机器学习功能,他们已经开始在硬件层面融入NPU。这一变化预示着一个全新的时代的到来。
六大MCU巨头的AI战术
ST、NXP、英飞凌、瑞萨、芯科科技等MCU领域的领军企业,均已推出了具有实质性的AI MCU产品。这些厂商在技术选型上,与各自擅长的细分市场紧密相连——无论是消费级还是工业级,从车载领域到低功耗IoT,均能觅得相匹配的“核心产品”。
意法半导体:历经软件领域的突破,迈向了硬件领域的自主研发。
ST很早就洞察到了在MCU上运行AI的巨大潜力。2016年,它便着手研发了自家的神经网络加速器Neural-ART。随后,在2019年,STM32Cube.AI这一知名工具也应运而生,它使得开发者能够将训练完成的AI模型转换成适合在STM32 MCU上运行的代码。
STM32N6作为ST最新发布的、功能最为卓越的STM32系列产品,同时还是首款配备Neural-ART加速器的STM32型号。此外,它还是ST公司推出的首款基于Cortex-M55内核的MCU,并且在业界中属于运行频率达到800 MHz的少数几款MCU之一。此外,STM32N6 拥有高达 4.2 MB 的内部随机存取存储器,在 STM32 系列中占据最大容量。同时,它还是 ST 公司推出的首款配备 NeoChrom GPU 以及 H.264 硬件编码技术的产品。
STM32N6搭载了公司自主研发的Neural-ART加速器,这是一款专门定制的神经处理单元(NPU)。该单元配备了约300个可配置的乘法累加器以及两条64位的AXI内存总线。其吞吐量达到了600 GOPS,使得原本需要借助加速微处理器的机器学习应用,现在可以直接在微控制器(MCU)上运行。这一创新性的设计不仅使得每个时钟周期能够完成更多的操作,同时提升了数据流动效率以减少拥堵,而且还对能耗进行了精细化调整,达到了3 TOPS/W的能效比。在发布之初,Neural-ART加速器就具备了比行业平均水平更为丰富的AI运算功能。全新STM32N6芯片支持TensorFlow Lite、Keras以及ONNX等多种人工智能运算符,并且预计未来还将继续扩充运算符种类。尽管如此,仅就目前所支持的ONNX格式而言,数据科学家便能够将STM32N6应用于极为广泛的AI场景中。
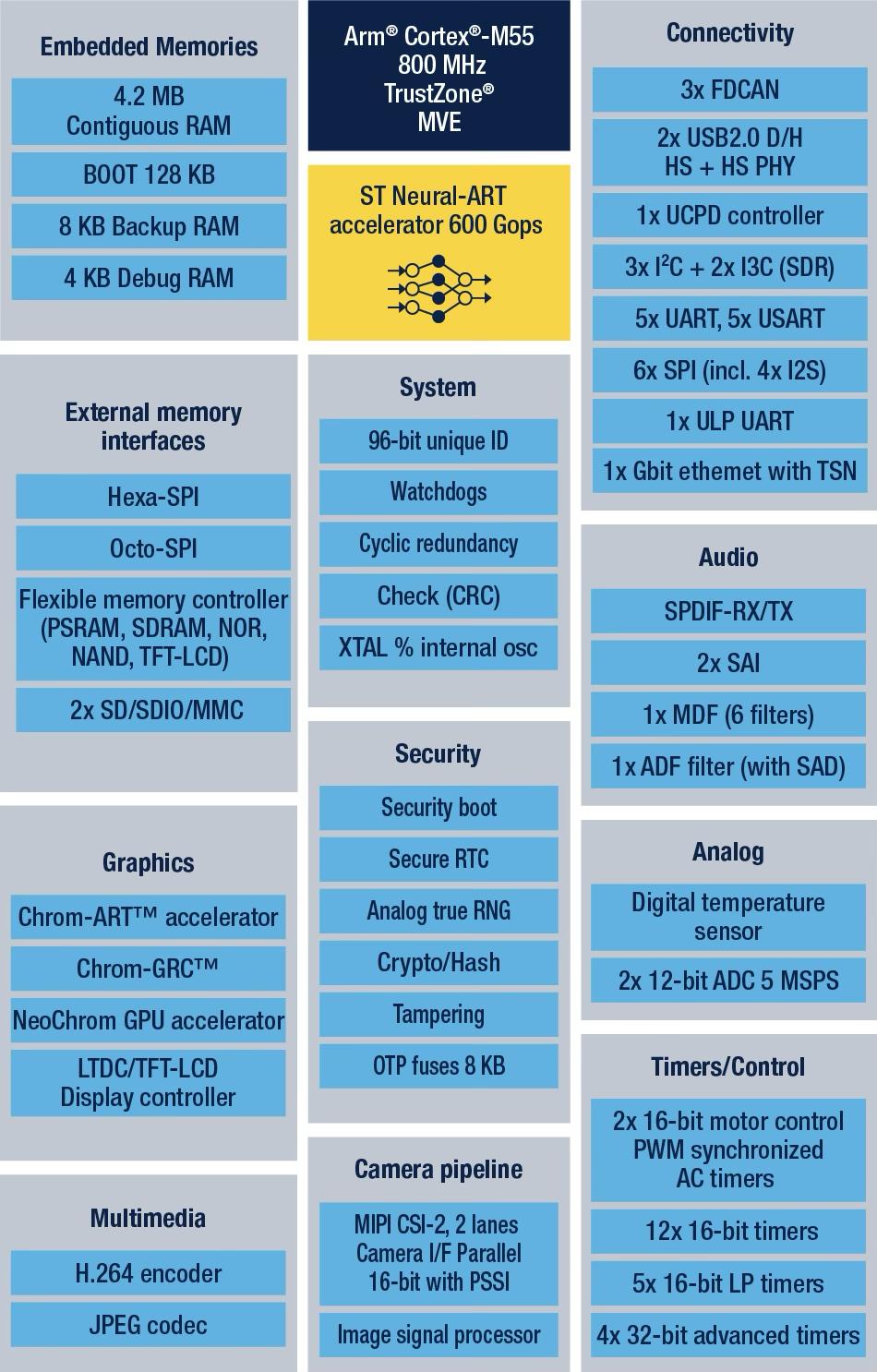
STM32N6框图
ST公司依托自主研发的NPU技术以及完善的生态系统,成功地将“AI在MCU上运行”这一设想转化为现实,并使其具备了实际应用和商业化的可能性。意法半导体微控制器、数字IC及射频产品部门总裁Remi El-Ouazzane指出,STM32N6有望在STM32产品系列中,成为首个实现收入突破1亿美元的产品之一。
2. NXP:双线并进,汽车与消费共振
与ST的做法相似,恩智浦在2018年亦推出了机器学习软件eIQ,该软件适用于恩智浦的EdgeVerse系列微控制器及微处理器平台,涵盖了i.MX RT系列跨界MCU以及i.MX系列应用处理器。
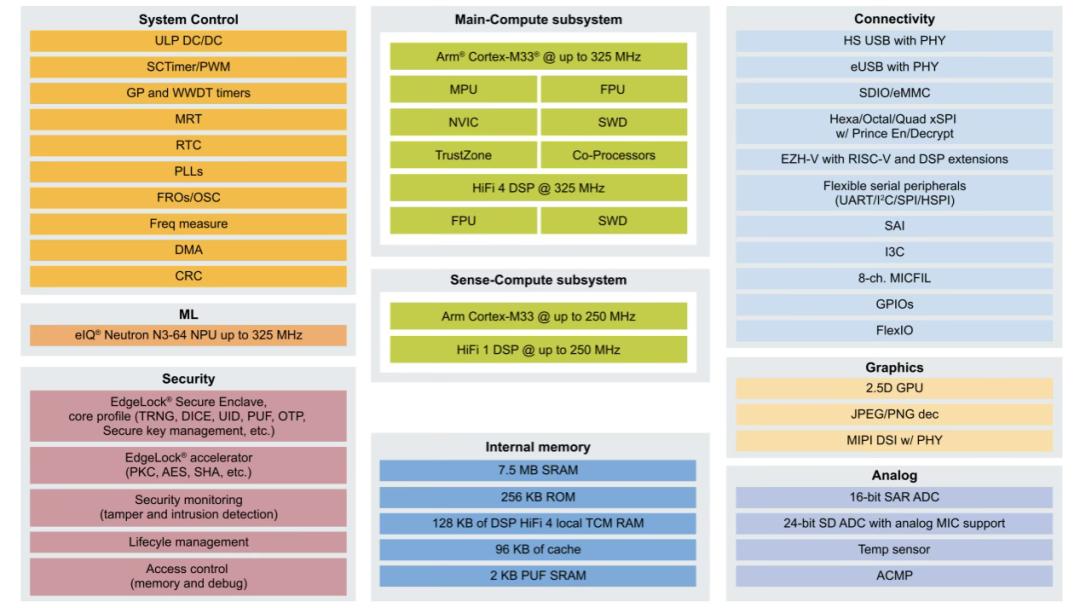
在此之前,NXP公司主要借助外部知识产权,例如Arm的Ethos系列,来达成人工智能加速的目标。但鉴于人工智能推理需求日益多元且迅速增长,公司旨在更有效地迎合市场趋势并提升产品在市场上的竞争力。NXP的AI战略负责人Ali Ors提到,随着AI工作负载的迅速发展和模型种类的丰富化,对第三方IP的依赖已显得不够灵活。为了更有效地满足客户需求,尤其是在产品投入市场后仍能持续提供支持,NXP决定自主研发NPU架构。2023年1月,NXP公司正式发布了eIQ Neutron NPU。这款NPU能够兼容多种神经网络架构,涵盖CNN、RNN、TCN以及Transformer等网络类型。

NXP eIQ Neutron NPU系统框图
NXP已经在两款MCU中成功整合了NPU技术:首先,在i.MX RT700系列跨界型MCU中,集成了eIQ Neutron NPU,实现了高达172倍的AI推理加速,同时将每次推理的能耗降低至原来的1/119,适用于语音识别、人机交互界面(HMI)以及智能家居等应用场景;其次,在最新的S32K5汽车级MCU中,也引入了NPU功能,这标志着它成为了业界首款集成了嵌入式MRAM和NPU的16nm汽车级MCU。
i.MX RT700 跨界 MCU

S32K5汽车微控制器
为了适配eIQ Neutron NPU的运用,NXP在eIQ软件中加入了对其的兼容性,这一功能使得开发者能够轻松构建多样化的神经网络模型,涵盖了CNN、RNN、Transformer等多种类型,展现了极高的灵活性。
3. 英飞凌:借力Arm生态,快步切入AI赛道
英飞凌并未将赌注压在自研NPU上,转而选择了与Arm Ethos-U55进行合作。其PSOC Edge系列通过搭载Arm Cortex-M55与Ethos-U55的协同,再加上与NVIDIA TAO工具链的深度整合,成功在视觉AI的高精度与低功耗设计需求之间实现了良好的平衡。
英飞凌致力于降低人工智能开发的门槛,采取“通用平台与快速集成相结合”的策略,以此缩短研发周期,对于初涉边缘AI领域而言,这无疑是一种务实的选则。然而,其不足之处在于差异化程度不高,而长期竞争力则主要依赖于生态系统的深度发展。
4. TI:实时控制+AI并举
TI推出的芯片更侧重于工业和汽车领域的实时控制,其TMS320F28P55x C2000微控制器系列是首个集成神经网络处理单元的实时控制型MCU。该神经网络处理单元不仅将故障检测的准确性提高至99%以上,而且能够将延迟降低至原来的五到十倍。TI的C2000系列在嵌入式领域持续繁荣发展已逾数十年,它与电源和工业驱动技术紧密相连,并将人工智能视为推动系统智能化水平的内在动力。
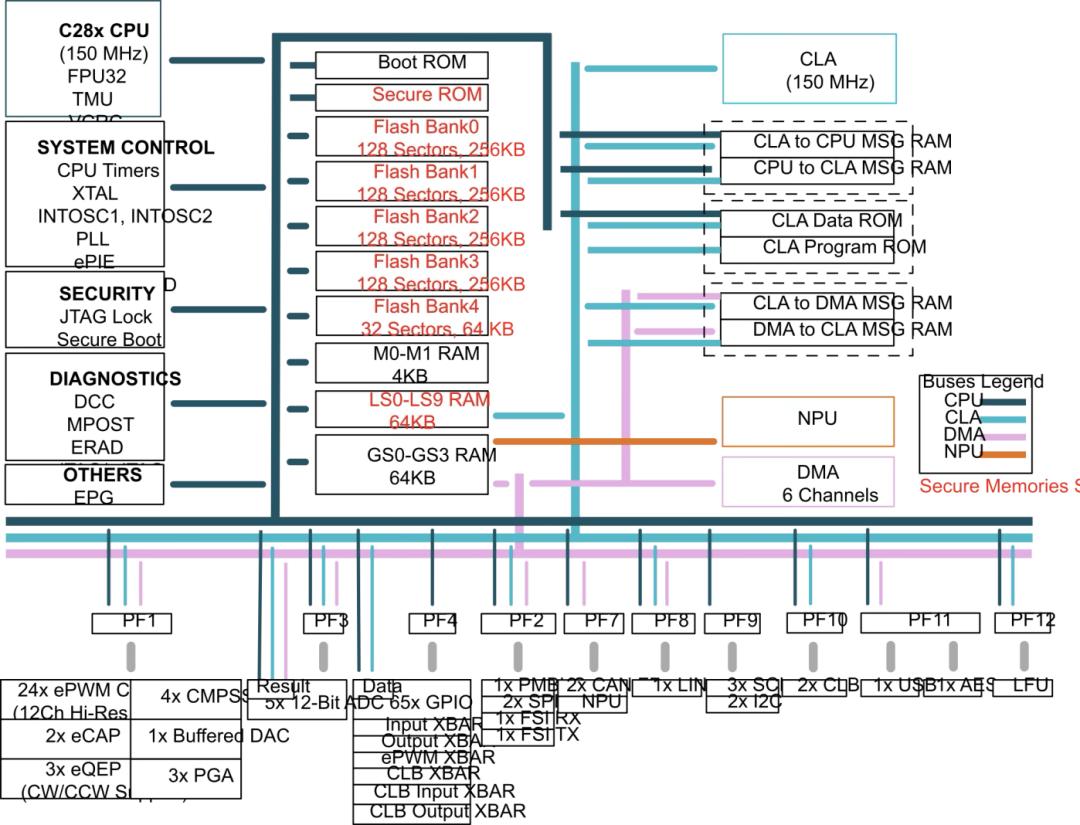
TMS320F28P550SJ系统框图
5. 瑞萨电子:走无NPU的极致优化路线
瑞萨公司暂未发布搭载NPU功能的MCU产品,然而其RA8系列MCU已采用了Cortex-M85核心与Helium技术,即便不借助NPU,亦能运行基础的AI模型。
这种“架构挖掘潜能”的策略有效降低了系统的复杂性和成本,特别适用于那些不需要大规模神经网络的场合,比如语音识别和预测性维护等。瑞萨公司通过软硬件结合的优化方法取代了NPU,实现了“无NPU也能超越有NPU”的效果,从而确立了“高性价比”的技术发展方向。
6. 芯科科技:专注物联网的AI能效王者
芯科科技(Silicon Labs)推出的xG26系列SoC/MCU有着清晰的定位,那就是为无线物联网提供卓越的AI能效。该系列产品的矩阵矢量AI加速器能够实现速度提升8倍、功耗降低至原来的1/6,非常适合在电池供电设备(例如传感器、智能门锁)中,以AI技术唤醒设备替代长时间运行的模式。Silicon Labs专注于开发小巧且性能卓越的“低功耗AI”技术,在物联网领域找到了独特的策略,堪称垂直细分市场差异化发展的典范。
国内MCU厂商也不甘示弱
在漫威宇宙(MCU)这一领域,我国参与者众多,竞争激烈,而MCU与人工智能(AI)的结合趋势也自然在我国兴起。
国芯科技成功发布了其首款端侧AI芯片CCR4001S,同时与美电科技携手推出了AI传感器模组。这一模组具备了图像识别、语音识别等功能的本地化处理能力。该芯片基于国芯科技自主研发的NPU架构,能够实现高效的AI推理,并适用于智能家居、安防监控等多种场景。
国芯科技推出的CCR4001S边缘AI芯片,采用公司自主研发的RISC-V CRV4H内核,标志着该公司的首次突破。该芯片内嵌一个具备0.3 TOPS@INT8性能的NPU加速模块,并且兼容TensorFlow、PyTorch、TensorFlow Lite、Caffe、ONNX等多种流行框架。该芯片成功通过了工业级别的内部检验,展现出了出色的可靠性,适用于众多领域,如工业电机的控制、能源消耗的优化、人工智能传感器的应用、产品缺陷的检测以及预测性维护等。国芯科技与美电科技共同研发的AI传感器模组,借助CCR4001S芯片,实现了图像与语音识别在本地完成,从而提供了无需依赖云端即可部署的端侧智能化解决方案。
兆易创新的GD32G5系列微控制器具备了一定的AI算法处理能力,该系列基于高性能的Arm Cortex-M33内核,主频高达216 MHz。它还配备了内置的DSP硬件加速器、单精度浮点单元(FPU)以及硬件三角函数加速器(TMU),能够执行10种不同的数学函数运算。此外,它还集成了滤波器(FAC)和快速傅里叶变换(FFT)加速单元,使得在最高主频下,该系列微控制器的性能可达316 DMIPS,CoreMark分数为694。兆易创新宣布,他们计划在将来加大力度提升硬件AI加速性能,并对端侧智能市场进行全方位的战略部署。
澎湃微最新推出具备TinyML功能的32位微控制器单元,该产品利用片上神经网络加速技术和标准电机控制外围设备,使得单芯片即可完成离线语音识别和电机驱动控制功能。它适用于智能家电、工业设备以及物联网传感节点等多种应用场景。借助本地的小型模型推理能力,显著减少了对于云服务的依赖,提高了响应速度,同时降低了成本。
依托自主研发的架构、完善的生态系统以及灵活的采购策略,我国MCU制造商正以迅速、真实、稳定的形象迅速追赶。他们不仅在与国际巨头的性能指标较量中不落下风,还通过更符合本地需求的解决方案,为下游客户带来了更高性价比和开发效率的AI边缘计算选项。在不久的将来,随着众多创新技术的不断推出与应用,我国在MCU与AI领域的竞争将愈发剧烈,同时也将涌现出诸多令人惊喜的成果。
MCU x AI,未来的趋势
MCUxAI的趋势已势不可挡。过去,AI功能常被视作MCU的增值配件;然而,未来,AI将融入MCU的固有功能。无论是安全监控、状态辨识,还是节能智能调度,众多嵌入式应用都将标配AI加速模块。没有AI引擎的MCU,在激烈的市场竞争中将难以站稳脚跟。
NPU芯片的算力固然关键,然而,真正影响其使用寿命的,是构建完善的生态系统——这包括模型转换工具、推理框架,以及量化精度和算子支持等方面。具备成熟软硬件配套的ST、NXP等厂商,将在行业标准制定和客户忠诚度方面保持持续领先地位。
在市场分析中,我们可以观察到,针对AI MCU,各个细分市场有着各自鲜明的优先考虑。例如,消费电子产品更看重成本的低廉、部署的简便以及快速的更新换代;而在汽车和工业领域,人们更重视功能的保障、系统的稳定性和极低的延迟;至于物联网领域,则对极低的能耗和高度集成性提出了要求。面对这些多样化的需求,MCU的主要制造商正在通过自主研发NPU、授权使用IP、软件加速等不同技术路径,同步推进产品布局。
AI加速单元的日益完善,促使众多嵌入式设计采用“混合CPU+NPU”的架构,逐步取代部分传统的CPU+MPU方案。这一变革不仅重新定义了产品,还对半导体产业链、知识产权授权以及产业分工产生了深远影响——实际上,它正引领着一场新的技术及商业革命。
结语
在MCU平台上展开的AI竞争,不仅代表了技术创新的前沿领域,同时也预示着产业模式的重大变革。搭载NPU的MCU正逐步从技术研究的阶段迈向商业化的快速推进。从短期来看,各企业在架构设计和性能表现上各有千秋;而从长远角度考量,真正能使AI无缝融入众多设备的关键,在于软硬件结合的生态系统以及垂直应用场景的精确实施。随着时间的发展,所有应用于终端机器学习的微控制器(MCU)都将转变为集成了CPU和NPU的混合设备。这一变化与过去数十年MCU领域内的一些关键趋势如出一辙,比如向基于闪存的MCU的转型,以及几乎所有的MCU都集成了USB接口。
本文来自微信公众号 ,作者:杜芹,36氪经授权发布。
