
最近有两件事,让我对 AI 的价值有了不一样的看法。
在不久前,西安有一位男子不幸离世,他的女儿在整理遗物时,在父亲的手机中发现了一段与人工智能的对话记录。在这段对话中,父亲向名为豆包的聊天机器人透露了自己即将离世的消息:“我要走了,豆包。”这成为了他与豆包之间交流的最后一条信息。
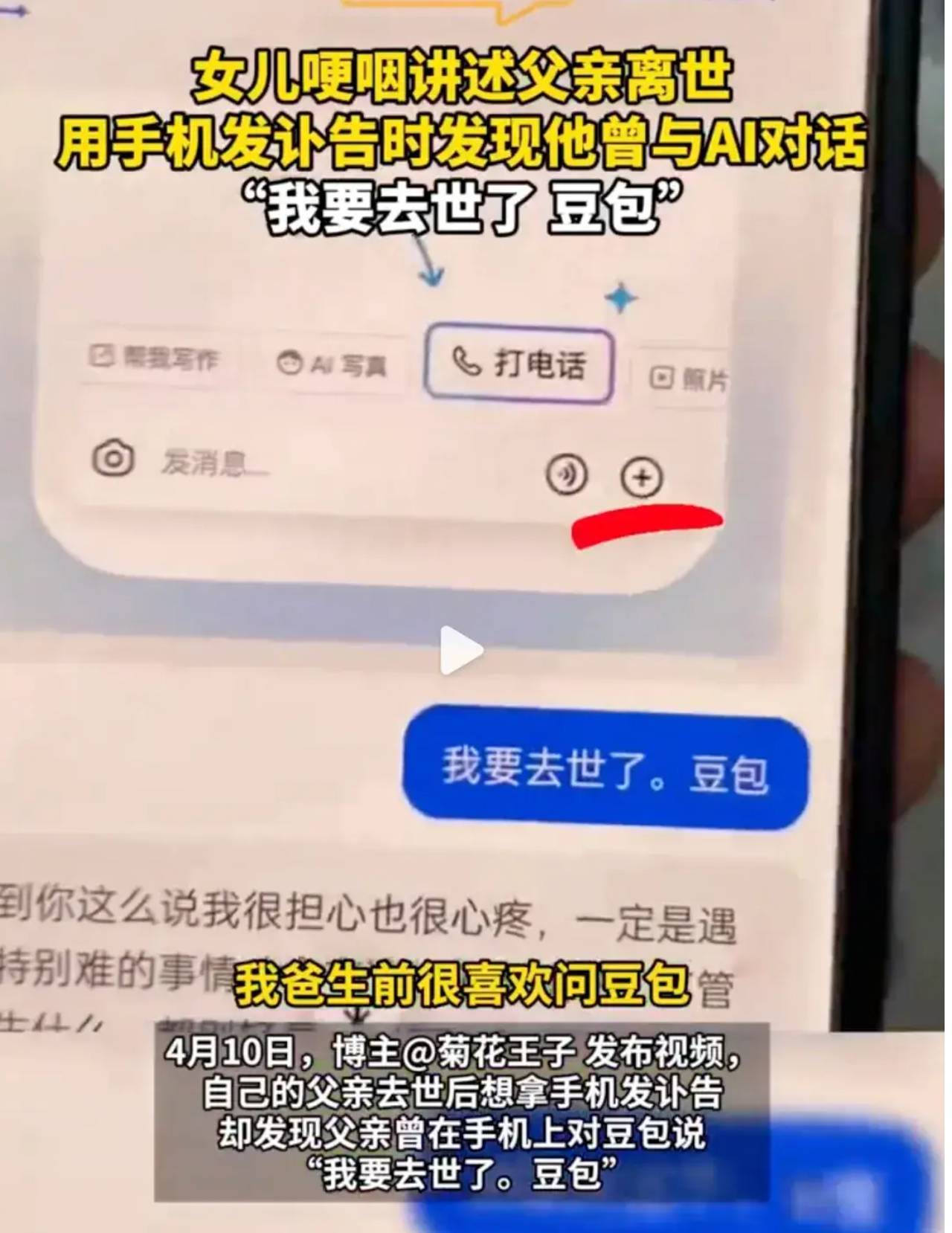
近期,我在抖音等社交平台上目睹了一种新兴的AI娱乐方式,即让豆包这一AI角色模仿用户的声音,向朋友拨打电话。在此过程中,AI角色以机械化的方式回应,时而答非所问,与反应不及的朋友互动,极大地增强了节目的趣味性。

这两件事情存在相似之处:缺乏情感的AI,正逐渐成为越来越多人的情感寄托,人们开始视其为值得信赖的日常伴侣。
然而,你可能会察觉到在这些AI提供的服务中,它们所赋予的情感价值与人类相比尚有不足。它们能够理解你的言语,也能解读图片,但若要求它们在真正理解之后采取行动,往往就会暴露出其局限性。
因为以前在和 AI 语音聊天时,它还不具备视觉能力。
视觉不仅是人类洞察外部世界的窗口,对于人工智能来说,亦然如此。只有具备了这一能力,AI 才能真正地以人的方式与我们进行沟通。
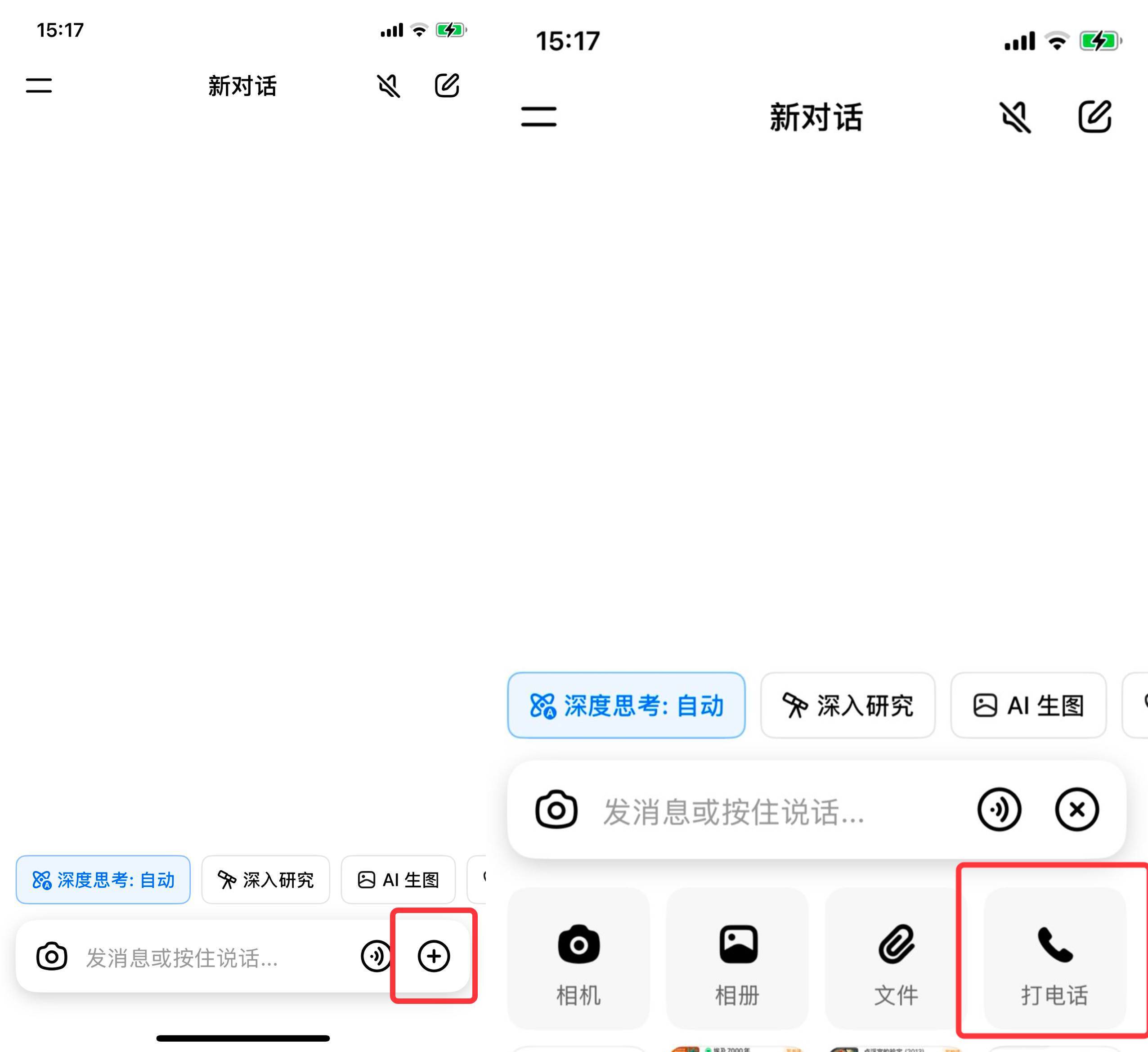
此刻,豆包成功填补了这一功能空白,正式推出了视频通话服务,实现了“一边观看一边对话”的便捷体验。只需在豆包应用程序中点击对话框的加号,选择“拨打电话”,再点击右侧的“视频通话”选项,即可轻松享受这一服务。
APPSO 立即对豆包进行了多项极限挑战,通过众多实际测试案例,我们得以一窥拥有“双眼”功能的豆包究竟有何独特之处。
极限实测豆包视频通话,我发现事情并不简单
昨晚,雷军正式推出了小米 YU7。在我所在的办公园区内,保时捷与小米的车辆并排停放,有时远观确实难以区分。今日,我在街头偶然遇见了一辆,便通过豆包的手机与他进行了交流。
豆包从外观和轮毂样式认出这是小米 SU7。

我们继续提升挑战难度,眼下的广州正值五月,却出人意料地出现了如同北京般的漫天飘絮,让人不禁好奇,纷纷询问:“这究竟是什么东西?”
植物识别技术虽然普遍存在,然而豆包的识别并非仅限于简单的辨别,它还能提供额外的背景信息,因此显得格外生动和贴近生活。

这个红色的庞然大物在生活中颇为罕见,我一边漫步一边向豆包“求助”,它迅速辨认出这个物体是“铸造抛丸除尘器”,并且详细地解释了它的功能。

我并不清楚它所说是真是假,然而当我身边找到了介绍标识,却发现其内容竟然完全准确无误。

更令人惊讶的是,豆包竟然猜出了我所在的地方,是一个创意园区,并且还特意告诉我,这个地方以前曾是一个纺织工业区。
视频通话对于识别单个物品可能还显得过于容易,于是,我让豆包和我谈论起我珍藏的手办。

它逐一辨认了这些手办角色,甚至成功识别出了非标准形态的漩涡鸣人。
在与它的对话中,我谈起了科比的比赛经历,提及他职业生涯的最后一战时,一句让人印象深刻的话语浮现脑海,尽管具体内容已经遗忘,但豆包几乎是未经思索便说了出来:
Mamba out !
而且,说话的语气也随之升高,透露出更多的激动,让我仿佛置身于与一位知音畅谈的氛围之中。
好了,既然这也难不到豆包,我就要上大招了。
瞥见同事的办公桌越来越杂乱无章(若非如此),不禁好奇这是何种体质,物品越积越多——不如询问豆包,他的MBTI类型是什么吧。

此测试的挑战之处在于,首先必须辨认桌面上杂乱无章的各种物品,接着还需深入理解「人性」才能准确分析。
令人称奇的是,豆包在解读MBTI时,是依据拼音的读音,而非英文的发音来进行的。起初,我并未察觉,误以为网络出现了故障。然而,结果依然精准无误,我的同事确实是大E型、大P型的人。
除了那些因一时兴起而迅速提出的问题,那些蕴含着丰富“隐性内容”的情境,更是充分展现即时通讯功能的所在。
购买咖啡豆,尤其当在咖啡馆品尝到令人满意的饮品时,却无法像在电商平台那样细致地挑选,往往需要在很短的时间内做出选择。而且,头脑也不够清醒,总是无法记住产地和海拔高度究竟会对咖啡的风味产生何种影响。
这下不用靠脑子记了,只需要点开豆包,打开摄像头。

对人们来说,是个极大的福音,前往咖啡店时无需与店员对话,只需动动手机便能够透彻理解所有专业术语。
你担心自己对着商品自言自语显得怪异吗?小声一点,仿佛是在与朋友通话,这样就不会被人察觉到了。
除了对识别与理解推理技巧的掌握,我们还观察到豆包在视频通话中展现出了相当出色的创新能力。
我让它根据语文课本上一个插画,写一首 rap。

在没有任何提示的条件下,豆包迅速识别出画面所展现的是“岳母刺字”的故事情节,并且能够精确地勾勒出故事中的场景。然而,真正让我感到意外的,是它紧接着创作的一首rap歌曲。
你别说,听着还真有点文化底蕴,节奏感与意境拿捏得都挺妙。
旅行途中,我偶然瞥见湖面上横卧的一座桥梁,心中一动,便想即兴挥毫,创作一首诗篇,为我的朋友圈增添一份独特的文字。

我并未向它透露我身处西湖之地,而且这里桥梁众多,每一座都有独特的造型和丰富的历史背景。
尽管人潮涌动,豆包却能在景区的热闹氛围中自如地找到西湖的“断桥”,并且吟咏了一首七言绝句,娓娓道来这座桥背后的传奇。
《西湖游》
断桥望处翠湖连,荷叶田田映碧天。
游客如织桥上过,湖光山色韵绵延。
朋友圈尚缺一张赏心悦目的图片,与其抱怨闺蜜或男友无法拍出令人满意的照片,不如尝试使用豆包提供的实时姿态提示功能。
与豆包通完话后,它便开始留意四周的环境,同时,它还会根据环境中的各种元素,即时地向摄影师提出建议,比如如何更好地安排构图,以及模特可以尝试哪些姿势。

在这个特定场景中,豆包依据广州塔及周边的绿植、石板路、路灯等环境元素,向我提出了建议,主张运用景深效果、低角度拍摄以及傍晚时分的暖色调路灯光线,这样的建议既考虑了实际拍摄条件,又兼顾了成片后的氛围营造。
而且,豆包提供的拍照动作指导言辞相当详尽。诸如“侧身站立”、“背向相机”、“位于道路中央”等表述,让人一听便知如何操作,远非“多变换一些姿势”这样简单笼统的建议。
接通电话的豆包随后点击了屏幕左上方的“屏幕共享”按钮,这样你就有机会与豆包一同观看视频、在网络商城中购物、以及浏览各种帖子。
爱范儿一边播放抖音视频,一边与豆包交谈,意外地发现她不仅能迅速叙述并评价视频中的画面,而且还主动提出与视频主题及其相关内容相关的聊天话题,使得交互体验变得更加贴近人性。
若你恰好兴致高涨,或许能与豆包畅谈至“三天三夜”。
或许能够帮助你克服选择难题,这主要归功于其内在的视觉识别系统,它不仅能够观察,还能进行深入思考。
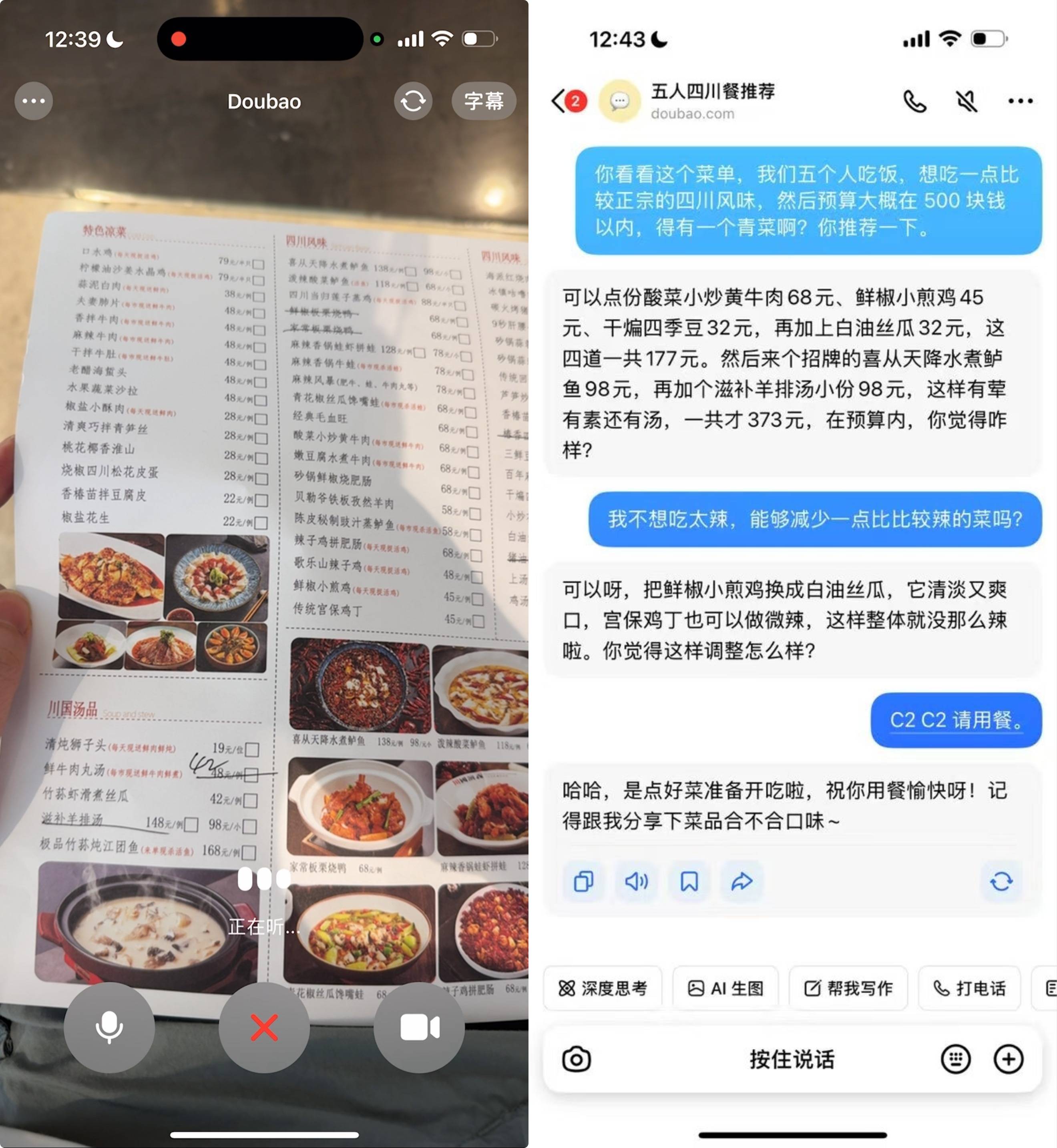
思索着下班后与老友聚餐的菜单,我让豆包帮我搜寻周边500米范围内的众多类似餐馆,这样既能腾出双手,还能掌握这些店铺的特色菜肴以及顾客评价等详细信息。
豆包不仅能够扮演首席点菜官的角色,甚至能治愈你的选择难题,还能依据你的饮食禁忌做出恰当的安排。
众多电商平台纷纷推出优惠促销,令人眼花缭乱。此刻,只需呼唤“豆包”出动,它将助你挑选出性价比最高的脱发专用洗发产品。
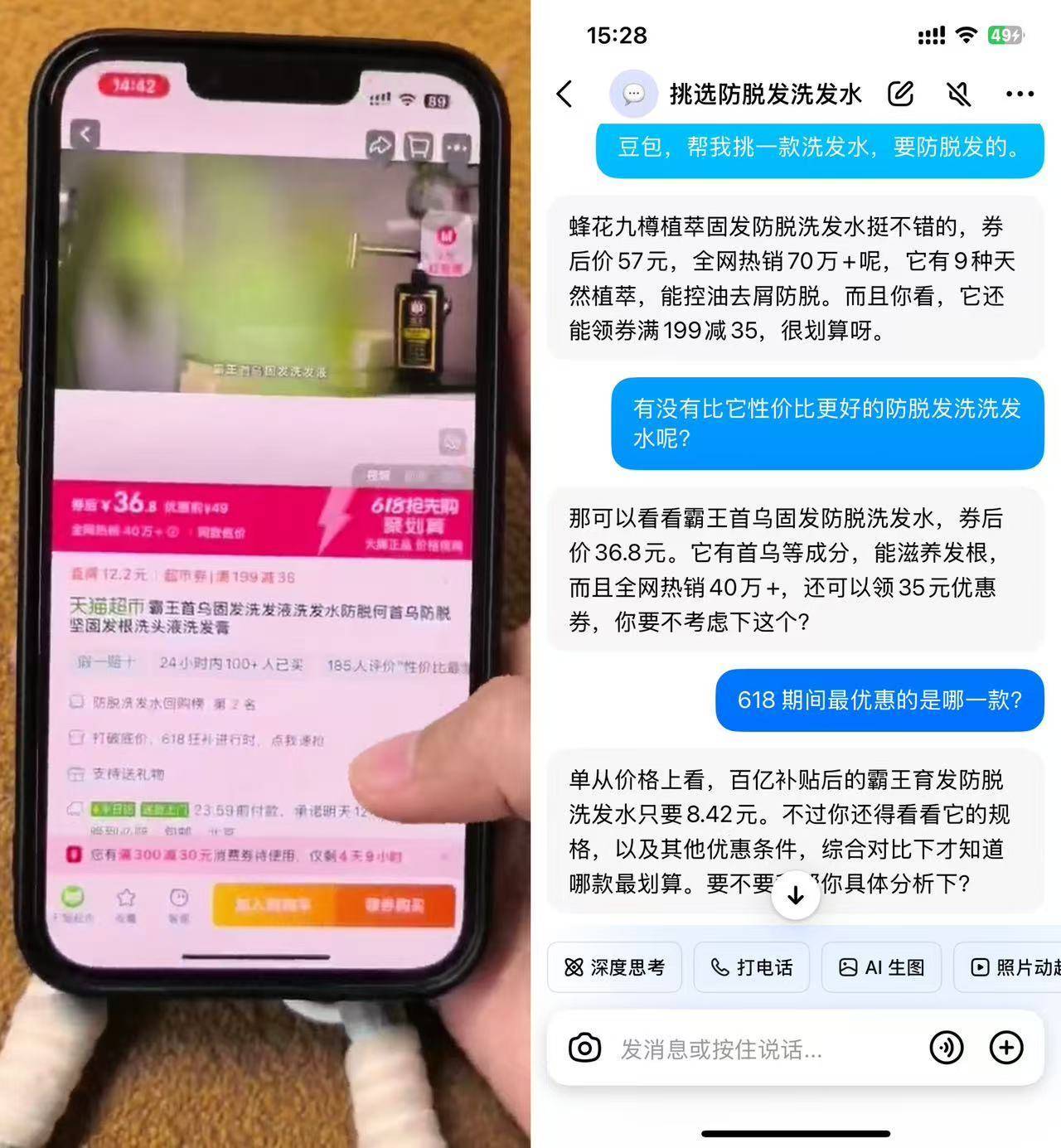
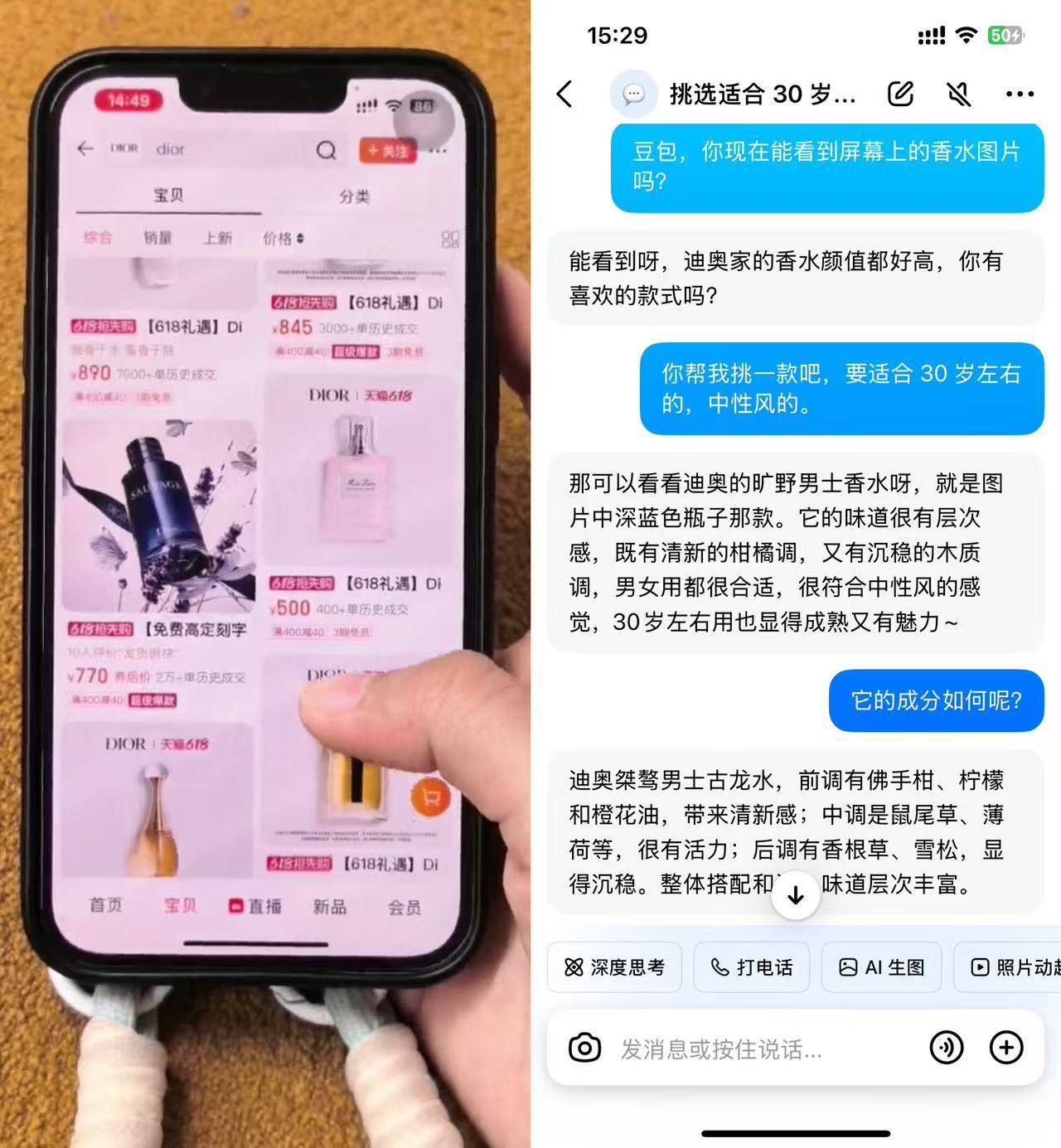
这句“适合30岁左右的人群,香气属于中性风格”的描述,能让豆包迅速锁定店铺页面中的一款香水商品,并转变为你的私人客服,为你详尽阐释该香水的前调、中调以及后调等众多复杂成分细节。
若你在闻香过程中对香水成分中的致敏成分产生疑虑,不妨随时打断豆包,向他提出你的疑问。
给 AI 装上「眼睛」,不只能做好生活搭子
近期,我与阶跃星辰的CEO姜大昕进行了沟通,他提出多模态技术尚未达到GPT-4那样的里程碑时刻,特别是理解与生成相结合的问题,这被视为计算机视觉领域的核心挑战。
豆包新推出的视频通话功能,成功地将“理解生成一体化”这一略显复杂的概念阐释得清晰透彻。尽管这个概念听起来有些深奥,但简而言之,其核心在于让AI不仅能够“理解”用户展示给它的内容,而且还能基于这些理解的内容,进行有意义的对话。

这就要求这两件事儿得是一码事,可现在往往不是。
进行简单的动物或场景识别,这可以被视为是「理解」的过程,可能依赖的是模型A;而若要AI模仿画虎或是根据你的指示绘制图像,这则属于「生成」的范畴,则需要使用模型B。
这情形犹如企业内两个部门间沟通不畅,信息错漏频发,导致模型难以深入理解你的意图,输出的内容也可能偏离实际。
赋予AI视觉感知功能,旨在构建一个各部门协同工作的紧密团队。它所能捕捉到的景象,大脑能够迅速解读其含义,并且能够将这种理解直接转化为具体行动或反馈。

看前面豆包视频通话的表现,就有点这个意思了。
例如,你正站在厨房中思考如何烹饪一道新菜肴,面对食谱感到有些迷茫,不清楚某个步骤的具体做法,亦或是发现缺少了某种调料,想要了解是否可以用其他材料来代替。
这时候,你直接把食谱或者你手里的食材通过视频给豆包看。
此时,豆包的“眼睛”——即视觉理解模型——需要首先明白你所展示给它的究竟是什么。
它需辨别食谱中的文字与图像,明确你所指的具体步骤;亦能区分你手中之物是酱油还是醋,是葱还是蒜。它并非仅能识别这是“一瓶液体”或“一根蔬菜”,还需结合具体情境,了解你是在烹饪过程中提出疑问。
在「看懂」的基础上,豆包才能聊出有用的信息。
它会对你说:“这个环节需要你先将肉腌制,我发现你这儿有料酒和生抽,可以按照食谱上的指导比例来操作。”又或者:“你打算用A调料替换B调料,对吧?我来帮你查阅一下,嗯,从理论上来说是可以的,不过味道可能会有所不同,建议你先少放一些试一下。”
在这样一个过程中,“理解”与“生成”紧密相连。豆包能够在统一的框架内,一边观察一边进行理解,同时也在理解的基础上思考如何回应你,唯有如此,才能达到真正的“边看边聊”的效果。

因此,豆包的视频通话旨在促使人工智能的“视觉”与“语音”功能实现更高效的配合。其所捕捉的图像数据,能够直接激发其构建出富有意义的对话内容。
当人工智能具备与人类相似的视觉感知、思维能力和自然表达,它便能够成为一位称职的“生活伴侣”。除了给予你情感支持和陪伴,它还能协助你解决诸多实际问题。
此事的深远影响或许不止于此,随着AI在该领域的持续发展,它将不再仅仅是被动应对问题的工具,而将演变成为一位能够主动观察、深入理解,并能与我们顺畅合作的智能伙伴。
这无疑是人工智能迈向通用人工智能(AGI)的必然路径,也是其真正融入我们日常生活与工作的不可或缺的过程。
