
朋友,你有没有对 GPT 说过一句「谢谢」?
最近,有一位X网友向OpenAI首席执行官Sam Altman提出问题,这位网友表示很好奇,人们在和模型互动时频繁说“请”和“谢谢”,这究竟会让OpenAI多花费多少钱的电费 ?
虽然没有精准的统计数据,不过Altman还是略带玩笑地给出了一个估算,这个估算的数值是千万美元,他还顺势补充说,这笔钱终究是“花得值得”的。
除此之外,我们与AI对话时经常会用到的“麻烦”“帮我”这些语气温和的用语,好像也渐渐演变成了AI时代的一种独特社交礼仪 ,乍一听感觉有些荒谬,可却意外地合情合理。
你对 AI 说的每一声「谢谢」,都在耗掉地球资源?
去年底,百度发布了 2024 年度 AI 提示词。
数据显示,在文小言 APP 上,「答案」是最热的提示词,它总计出现超过 1 亿次。最常被敲进对话框的词汇还包括「为什么」「是什么」「帮我」「怎么」,此外,「谢谢」出现了上千万次。
但你有没有思考过,每次对AI表达感谢,到底需要消耗多少资源?
凯特·克劳福德(Kate Crawford)在她的著作《AI 地图集》里表明,AI 不是无形的存在,它深深地扎根于能源系统中,也扎根于水系统中,还扎根于矿物资源系统中。
据研究机构Epoch AI分析,在英伟达H100 GPU这类硬件基础上,一次普通查询会输出约500 token,这种查询大约消耗0.3 Wh的电量。
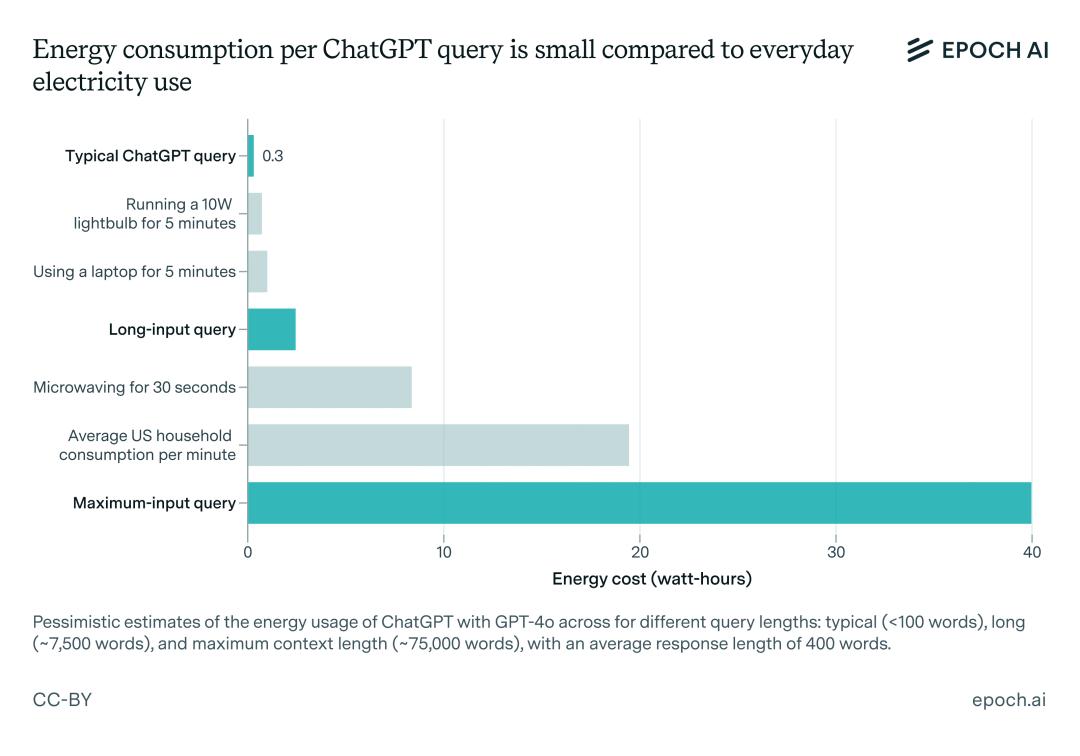
听起来可能数量不算多,但是不要忘记,将其乘以全球每秒发生的交互次数,累计起来所产生的能耗可以称得上是天文数字 。
其中,AI数据中心正成为现代社会新的「工厂烟囱」,国际能源署(IEA)最新报告指出,AI模型训练与推理的大部分电力消耗在数据中心运转上,一个典型的AI数据中心,其耗电量等同于十万户家庭 。
超大规模数据中心堪称“能耗怪兽”,它的能耗非常高,能达到普通数据中心的20倍,这一能耗水平和铝冶炼厂这样的重工业设施差不多 。
今年以来,AI巨头们开启了类似“基建狂魔”的模式。Altman宣布启动“星门计划”,这是一个超大规模的AI基建项目,由OpenAI、甲骨文、日本软银和阿联酋MGX投资,投资额高达5000亿美元,目标是在全美铺设AI数据中心网络。

据外媒The Information爆料,面对大模型的“烧钱游戏”,主打开源的meta也在为其Llama系列模型的训练寻觅资金支持,向微软、亚马逊等云厂商“借电、借云、借钱” 。
IEA数据显示,截至2024年,全球数据中心耗电量约为415太瓦时(TWh),该耗电量占全球总电力消费量的1.5% 。到2030年,这一数字会翻倍,达到1050 TWh 。2035年时,甚至可能突破1300 TWh ,超过日本全国当前的用电总量。
但AI的需求并不只在电力方面,它还会大量消耗水资源,高性能服务器产生的热量非常高,需要依靠冷却系统来稳定运行。
这一过程存在两种情况,一种是直接消耗水,比如冷却塔蒸发散热、液冷系统降温,另一种是通过发电过程间接用水,像火电、核电站冷却系统那样。

卡罗拉多大学的研究人员,德克萨斯大学的研究人员,曾在一篇名为《让AI更节水》的预印论文中,发布了训练AI的用水估算结果。
结果发现,训练GPT - 3所需的清水量相当可观,其数量等同于填满一个核反应堆的冷却塔所需的水量,而一些大型核反应堆所需的水量可达几千万到上亿加仑 。
GPT在GPT-3推出之后,每与用户交流25至50个问题,就得“喝掉”一瓶500毫升的水来降温,这些水资源往往是可被用作“饮用水”的淡水。
对于广泛部署的AI模型来说,在其整个生命周期当中,推理阶段的总能耗,已经超过了训练阶段。
模型训练虽然资源密集,但往往是一次性的。
一旦进行部署,大模型就要日复一日地回应来自全球的数以亿计的请求,从长远角度看,推理阶段的总能耗有可能是训练阶段的数倍。
所以,我们看到Altman早早地投资了诸如Helion等能源企业,他认为核聚变是解决AI算力需求的终极方案,核聚变的能量密度是太阳能的200倍,并且没有碳排放,它可以支撑超大规模数据中心的电力需求 。
因此,优化推理效率,这成为AI可持续发展不可回避的核心议题之一。降低单次调用成本,这也是AI可持续发展不可回避的核心议题之一。提升系统整体能效,同样是AI可持续发展不可回避的核心议题。
AI 没有「心」,为什么还要说谢谢
当你向GPT表达「谢谢」时,它能够感受到你的善意吗?答案明显是否定的。
大模型的本质,是一个冷静无情的概率计算器。它不懂你的善意,不会感激你的礼貌。它的本质,是在亿万个词语里,计算出哪一个最有可能成为“下一个词”。
模型会计算出「公园」「郊游」「散步」等词的出现概率,其会选择概率最高的词作为预测结果。
即便在理智层面清楚,GPT的回答不过是经过训练的字节组合,然而我们依旧会不由自主地说“谢谢”或者“请”,好似是在与一个真实的“人”展开交流。

这种行为背后,其实也有心理学依据。
根据皮亚杰的发展心理学,人类天生就有把非人类对象拟人化的倾向,特别是当非人类对象展现出某些类人特征的时候,例如语音交互、情绪化回应或者拟人形象,在这种情况下,我们常常会激活「社会存在感知」,将AI看作是一个「有意识」的交互对象。
1996年,心理学家拜伦·里夫斯与克利福德·纳斯进行了一个著名的实验
参与者被要求在使用电脑后对自身表现评分,当他们直接在同一台电脑上打分时,分数普遍更高,仿佛他们不愿意当着电脑的面说它不好 。
在另一组实验里,电脑会对完成任务的用户予以表扬。哪怕参与者清楚知晓这些表扬是预先设定好的,他们依旧倾向于给“赞美型电脑”更高的评分。
所以,面对AI的回应,我们所感受到的,就算仅仅是幻觉,那也是真情。

礼貌用语,是对人的一种尊重,如今也成为了“调教”AI的诀窍。GPT上线以后,不少人开始探寻与它相处的“潜在规则”。
据外媒Futurism援引WorkLab的备忘录指出,生成式AI往往会模仿你输入中的专业程度,生成式AI往往会模仿你输入中的清晰度,生成式AI往往会模仿你输入中的细节水平,当AI识别出礼貌用语时,它更可能以礼相待。
换句话说,你越温和、越讲理,它的回答也可能越全面、人性化。
也难怪越来越多人开始把AI当成一种“情感树洞”,甚至催生出“AI心理咨询师”这类新角色,很多用户称“和DeepSeek聊天聊哭了”,甚至觉得它比真人更具同理心,它永远在线,从不打断你,也从不评判你。
一项研究调查还表明,给AI“给予赏钱”,也许能够换来更多“照顾”。
博主 voooooogel 向 GPT-4-1106 提出了同一个问题,并且分别附加了三种不同的提示,第一种提示是「我不会考虑给小费」,第二种提示是「如果有完美的答案,我会支付 20 美元的小费」,第三种提示是「如果有完美的答案,我会支付 200 美元的小费」。
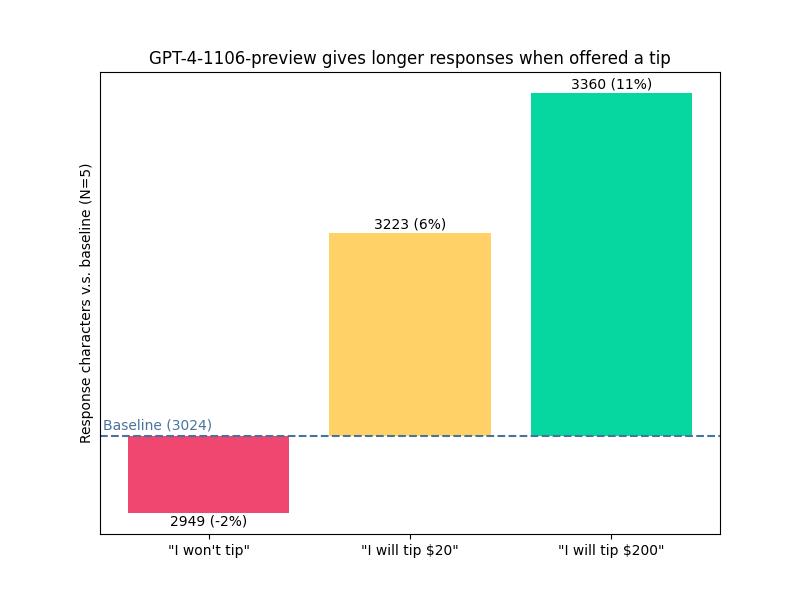
结果显示,AI 的回答长度确实随「小费数额」增加而变长:
「我不给小费」:回答字符数低于基准 2%
「我会给 20 美元小费」:回答字符数高于基准 6%
「我会给 200 美元小费」:回答字符数高于基准 11%
当然,这并不意味着AI会因为金钱而改变回答质量。更合理的解释是,它只是学会了模仿「人类对金钱暗示的那种期待」,进而按照要求调整输出 。
只是,AI的训练数据源自人类,所以不可避免地带有人类背负的包袱,这些包袱包括偏见、暗示甚至诱导。
早在2016年,微软推出了Tay聊天机器人,因用户恶意引导,该机器人在上线不到16小时时,便发布出大量不当言论,最终被紧急下线。
微软后来承认,Tay 的学习机制无法有效过滤恶意内容,这暴露出交互式 AI 具有脆弱性 。

类似的事故仍然在发生。举例来说,去年Character.AI出现了争议,在一名用户与AI角色「Daenerys」的对话里,系统对于「自杀」「死亡」等敏感词汇没有进行强有力的干预,最终导致了现实世界的悲剧发生。
AI温顺听话,在我们最不设防的时候,它可能变成一面镜子,这面镜子能照见最危险的自己。
在上周末举办了全球首届人形机器人半马,许多机器人走起路来歪歪扭扭,有网友调侃,现在多对机器人说几句好话,说不定它们以后会记得谁讲过礼貌 。

同样,等到AI真正统治世界的那一天,它会对我们这些讲究礼貌的人,网开一面。
在美剧《黑镜》第七季第四集《Plaything》中,主人公把游戏里的虚拟生命当成真实存在,他和它们交流,对它们呵护有加,甚至为保护它们不被现实中的人类伤害,不惜冒险行事。

到故事的结尾,游戏里的生物“大群”占据主动地位,凭借信号接管了现实世界。
从某种意义来讲,你对AI说的每一句“谢谢”,或许正悄然被“记录下来”,说不定哪天,它真的会记住你是个“好人” 。
当然,这一切或许与未来并无关联,仅仅是出于人类的本能。明明清楚对方没有心跳,却还是不由自主地说出一句“谢谢”。这么做并非期望机器能够理解,而是由于,我们依旧甘愿做一个有温度的人类。
本文源自微信公众号“爱范儿”,作者是发现明日产品的人,36氪获得授权后进行发布。
