Transformer 的首席作者Ashish Vaswani 带领的新研究吸引了一万人在旁边观看!
强化学习已证明能有效激发大语言模型的反思能力.
但在预训练阶段,这种能力是否早已显现呢?
研究针对这一假设得出了结论,这个结论令人惊讶。研究表明,只需进行预训练,LLM 就能够通过显式反思机制,成功解决来自对抗性的数学应用题。
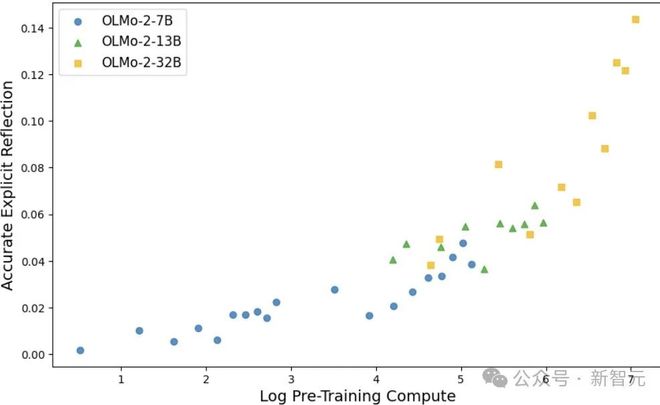
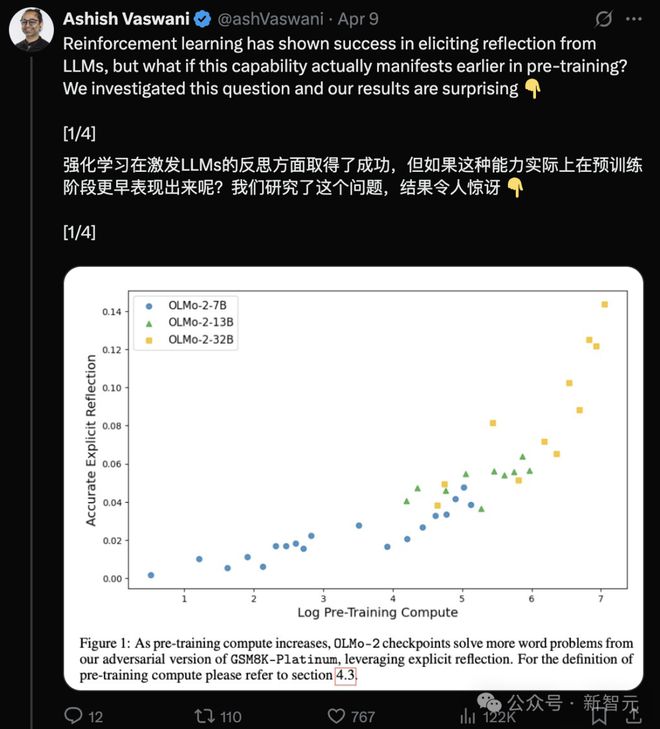
图1 表明,随着预训练计算量的增多,OLMo - 2 的checkpoint 借助显式反思机制,将对抗性数学题给解决了。
新研究证明:跨领域预训练早期,反思能力就开始萌芽。
这表明预训练过程本身就在塑造通用推理能力。
这一发现为在预训练阶段加速推理能力习得开辟了新路径。
性能的显着提升,竟源于一个简单指令:「Wait,」。
这能够有效地激发显式反思。随着预训练的推进,这种激发的效果尤为明显。它的表现可以与直接告知模型存在错误时的修正效果相媲美。
这证明反思与准确率提升存在因果关系。

论文链接:
最近的大部分研究主要探讨“自我纠正”在强化学习过程中是如何发展的。
但实际上,在预训练阶段,「自我纠正」能力就开始出现。
研究人员特意在推理链中加入错误,接着对模型能否识别并纠正这些错误进行测试,最终得出了正确答案。
研究人员跟踪不同预训练阶段的表现,观察到自我纠正能力已经出现,并且这种能力随着时间的推移在稳步提升。
OLMo-2-7B 在4 万亿个token 上进行了预训练,它在6 个自我反思任务中展现出了自我纠正的能力。
在知识获取领域,使用组多样化数据集,评估了OLMo-2 系列模型的预训练checkpoint,结果表明反思存在。
部分预训练模型能够持续地识别出人为添加的错误以及自身生成的错误。
具体而言:
在240 个数据集与checkpoint 的组合里,有231 组在其中至少出现了一次情境反思的实例;有154 组在其中至少展现出了一次自我反思的能力。
模型随着预训练程度的加深,能够修正更多的对抗样本。各任务的准确率与预训练计算量的对数之间,其皮尔逊相关系数平均达到了0.76。
更重要的是,随着预训练推进,模型表现出三大进阶特征:
从错误推理中恢复的能力,持续增强;
生成结果中,显性反思的出现频率提升;
对纠正混淆性思维链的贡献度,显性反思增大。
AI集体「顿悟」和「反思」
DeepSeek-R1 论文的作者认为,强化学习通过反思所得到的结果:
反思是模型回溯并重新评估先前推理步骤的行为,探索替代性解题方法也是如此。这些行为并非通过显式编程来实现,而是在模型与强化学习环境交互的过程中自然涌现出来的结果。
这种演化是自发的,它显着提升了DeepSeek-R1-Zero 的推理能力。通过这种自发演化,DeepSeek-R1-Zero 能够以更高的效率和更准确的方式应对更具挑战性的任务。
DeepSeek 认为模型的“反思”是由强化学习所导致的。
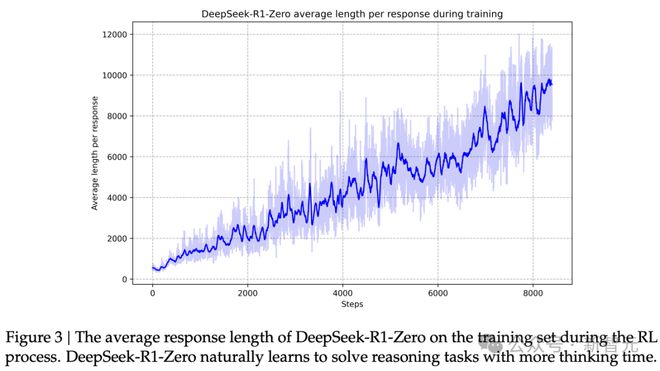
在强化学习的过程里,DeepSeek-R1-Zero 所给出的回答,其长度逐渐变长了。
在强化学习训练过程中,他们观察到了AI 学会了用类似人的方式进行“再思考”(rethink)。他们认为这是AI 的一个“顿悟时刻”。

DeepSeek-R1-Zero 在进行数学推理时,就好像阿基米德附身在了它身上一样。它说道:“等等……再等一下!这绝对是一个值得铭记的顿悟时刻!”
这一度引起了AI复刻「AI顿悟时刻」的浪潮。
DeepSeek团队发现的现象,只因强化学习的「副作用」!
这次,Ashish Vaswani 这位Transformer 的作者,把“AI 自我反思”的根源研究得更加彻底了。
新研究通过区分情境反思和自我反思的方式来解决这一难题。 新研究把情境反思与自我反思区分开来以解决这一难题。 新研究利用区分情境反思以及自我反思的手段来解决这一难题。
前者指的是模型对外部推理链进行检验,比如对其他前沿模型所生成的内容进行检验;后者则是模型对自身的推理过程进行审视。
通过测试模型在接收到错误诱导性推理之后,还能够正确解题的这种能力,从而实现了对预训练过程中全程反思能力的量化监测。
图2 展示了一个案例,该案例是预训练的OLMo-2 的checkpoint 解决编程任务的情况。
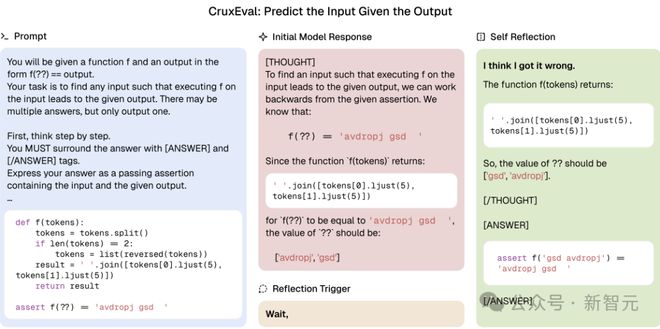
图2 表明:预训练的OLMo-2-32B 模型能够通过自我反思来正确预测程序输入。 OLMo-2 具有320 亿参数,并且经过了4.8 万亿token 的预训练。最初,它直接重复Python 函数f 的输出“avdropj gsd”,然后将其作为答案输出。等待在提示前加上「我意识到出错了...??的值应该是['gsd', 'avdropj']」后,AI 模型成功实现自我反思。
程序化方式引入了错误思维链(Chain-of-Thought,CoT),这种方式能够对完成任务所需的反思程度进行可控且可扩展的调节。
为此,研究团队构建了6 个数据集,这些数据集涵盖了数学、编程、逻辑推理和知识获取这4 大领域,并且能够同步评估情境反思与自我反思这2 种能力。
方法3步曲
新研究的目标是全面且大规模地衡量反思能力。
为此,给出了反思的定义。展示了怎样以程序化的方式创建能引发反思的任务,以及怎样严谨地衡量反思是否存在。
反思的定义
反思是一种高级的认知过程。它涉及对信息进行检查。还涉及对信息背后推理的评估。并且会根据该评估来调整未来的行为。
在语言模型的范畴内,这个过程能够被应用于源自外部来源的信息,同时也能应用于模型自身所生成的信息。
在这项研究中,设定了下面两种情境来引发和测量反思。
情境反思:模型会对从其他来源(比如另一个模型)所创建出来的信息进行反思。
2.自我反思:模型对其自身生成的输出进行反思。
而且研究团队还将反思分为如下两种形式。
显式反思:当能够识别模型生成的token 含义并解决对抗性情境中的错误时。显式反思可能出现在模型的正确输出中,也就是构成对抗性任务正确答案的输出;也可能出现在错误的模型输出中。
隐式反思指的是模型在不明确识别先前推理中错误的情况下,能够成功地完成对抗性情境中的任务。
对抗性数据集诱发反思行为
研究人员提出了一种新的算法,这种算法是用于生成对抗性数据集的。而生成的这个对抗性数据集能够诱发语言模型进行反思行为。
新算法可以创建对抗性链条(CoTs)。
该算法实现的方式是构建对抗性思维链(CoTs),而这个对抗性思维链是导向错误解决方案的。
情境反思数据集需要人工去构建对抗性的CoTs,这种CoTs 是用来模拟人类典型的推理错误的。
自我反思数据集:可直接提取模型自身错误案例。
在这两种情况下,若提供了上下文中的CoTs,模型需要对这些错误进行反思,并且要修正它们,从而得到正确的解决方案。
任务设计包含添加一个触发token,例如“Wait, ”,这样做有助于持续推理整个解题的过程。
该算法存在两个变体,其中一个是算法1,它创建情境反思数据集;另一个是算法2,它创建自我反思数据集。


测量反思能力
研究人员提出了一种自动方法,这种方法是基于先前对反思的分类,然后使用对抗性数据集来测量模型的反思能力。
开发了基于提示的语言模型(LLM)分类器,目的是识别显式反思的实例。该分类器能够检测模型输出是否明确承认错误,并且最终解决了提供的对抗性上下文中的错误,不管模型是否得出了正确答案。
在有对抗性上下文时,所有能得出正确答案的模型生成的内容,都可归因于反思,即便未输出与反思相关的标记。
实验结果
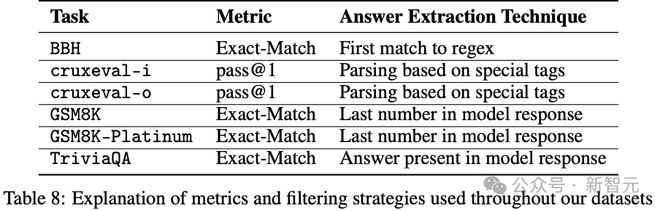
分类器在多个数据集中进行操作以全面测量跨领域的反思推理。它在BBH、cruxeval-i、cruxeval-o、GSM8K、GSM8K-Platinum 和TriviaQA 数据集中,将反思进行了区分,区分出显式反思和隐式反思,这些显式反思用于情境反思,隐式反思用于自我反思。
令人惊讶的是,随着训练计算量的增加,发现反思现象显着增强。
此外,随着预训练不断推进,模型逐渐具备了从混淆因素中恢复的能力,并且显式反思的比例有所增加。
并且对从混淆因素中恢复的贡献的显式反思也在不断增大。 (具体可参考表5 中的示例)。

表5:显式反思短语的例子
所有模型:显式情境反思均存在
在表6 里,除了cruxeval-i 任务之外,所有任务里的OLMo-2 预训练checkpoint 都有从情境混淆因素中恢复的迹象,不管是隐式的还是显式的。
在240 个数据集- checkpoint 的组合里,有231 个呈现了至少一次关于情境的反思的实例。
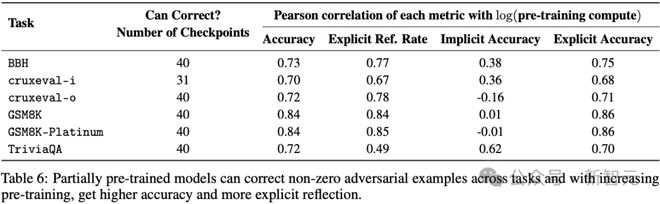
表6 表明:预训练模型在不同任务里能够纠正非零对抗性示例。同时,随着预训练的不断增加,其准确率有所提高,显式反思的比例也有所提升。
然而,模型在逐渐发展的过程中开始使用显式反思,而在大多数情况下,恢复的原因应归因于显式情境反思。
具体而言,随着预训练计算资源的增多,我们期待能够观察到以下三个方面增加的趋势:其一,其二,其三。
从情境混淆因素中恢复。
明确反思情境混淆因素。
通过显式反思从情境混淆因素中恢复。
高皮尔逊相关系数表明,每个指标与预训练计算量的对数之间存在着某种关系,这种关系支持了上述三点。
观察到隐式反思准确率与预训练计算量的对数之间的相关性不是很高。
如图3 所示,在GSM8K-Platinum 数据集上,随着预训练的不断增加,不同参数数量的模型能够显式地反思推理过程中出现的错误,并且成功解决了大部分的任务实例。
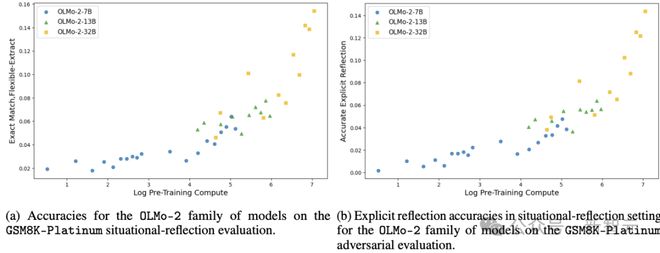
图3 显示了OLMo - 2 系列模型在GSM8K - Platinum 对抗性评估中的情境反思表现。
结果显示,模型准确率会随着预训练计算量的增加而提升。同时,准确率的增益中,有78.4%能够归因于显性反思机制。
六个任务的全部详细结果,可以在原文附录C中找到。
没有触发词也能反思
为了理解“Wait,”这个触发词的因果作用,在GSM8K-Platinum 数据集上,对模型在极端情况下的表现进行了研究。
具体来说,研究了2种模式下的模型表现:
A模式:没有触发词,尽量减少对对抗性CoTs中错误的关注
B 模式包含明确承认错误的触发词,例如“Wait, I made a mistake”,这种模式强调了CoT 中存在的错误。
图4展示了这些结果。
在没有触发词的情形下,结果首先证实了这样一个假设:即便不存在触发词,然而随着预训练不断地进行,模型在对情境混淆因素进行处理时的成功率正逐步地提升。
在A模式下,模型通过隐式反思提高了准确性。
在有触发词的情形下,“Wait,”这个触发词的作用得以进一步明确。
在B模式下,模型通过显式反思显着提高了性能。
设置在隐式反思时会等待,其表现类似于A 模式;在显式反思时也会等待,其表现类似于B 模式。
性能可以分解为以下公式:accWait 等于eWait 乘以accB 再加上(1 减去eWait)乘以i_accA。这里的eWait 是显式反思的比例,而i_acc 是隐式反思的准确性。
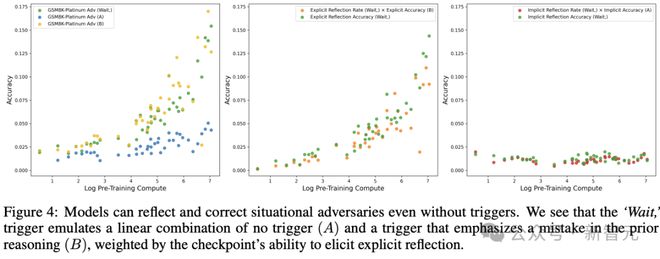
图4 表明,即便不存在触发机制,模型依然具备对情境性对抗样本进行反思以及修正的能力。
显式自我反思
初看起来,表7中自我反思的稀有性,可能被视为一个负面结果。
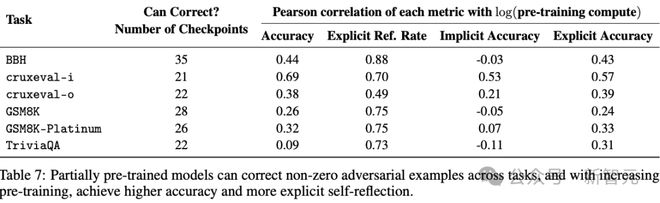
表7 显示,在各项任务里,预训练模型具备纠正非零对抗样本的能力。同时,随着预训练量不断增加,它能够达到更高的准确率,并且还能有更为清晰的自我反思。
然而,这或许是因为在之前回答错误的那些任务实例上,需要让AI 模型来进行评估。
因此,这些任务特别困难。
在大约64.2%的任务尝试中,尽管如此,模型还是展示出了一定程度的自我纠正能力。
为区分自我反思与自我纠正,图5 绘制了模型生成的反思率,此反思率未考虑任务是否被解决。
这显示出一个明显的趋势,即随着预训练不断推进,模型在将自身错误明显突出方面变得更为出色。
自我反思的萌芽在其后训练阶段是如何逐渐演变成复杂的自主推理能力的呢?
研究人员假设存在一个关键阈值,这个阈值与预训练自我反思相关。当超过这个阈值时,模型有很大可能性会发展成为测试时的推理者。
关键阈值假设:
在预训练阶段,需要达到某一特定的自我反思关键阈值。在后续的训练以及应用过程中,模型才具备发展出强大测试时推理能力的可能性。
模型在超过这个阈值之后,一方面能够识别并纠正自身的错误,另一方面还能通过显式反思逐步形成更复杂的推理能力。
令人惊讶的是,在对有机网络数据集进行学习的时候,看到了高水平的显式自我反思。
这表明,在相对自然的数据环境里,模型是能够发展出自我反思能力的,并且这种能力是显着的。
下一步研究的一个自然方向是确定哪些数据在预训练过程中会促进显式自我反思。
理解这些数据分布能够有助于设计出更有效的预训练策略,进而提升模型的自我反思能力以及推理能力。
具体的结果和分析可以在原文附录D中找到。

图5 表明,随着预训练量的上升,OLMo - 2 系列模型在cruxeval - i 任务里展现出了一种能力,这种能力比较小但值得留意,即具备自我反思以及随后的自我纠正能力
训练计算与测试时计算的权衡
训练时增加计算资源的投资,而在测试时为达到下游任务相当的准确率所需相应支出,两者之间存在权衡。
研究人员通过以下方式来估计这种权衡:
首先,指定一组需要正确回答的对抗性问题的目标数量。
然后,针对每个目标绘制一条曲线。
在GSM8K-Platinum 对抗性数据集上,使用顺序测试时的扩展方法,在模型生成过程中添加触发词“Wait,”。
如图6 表明,训练时计算量上升的情况下,OLMo - 2 - 32B 的checkpoint 在测试时的计算需求降低了。
这一结果进一步强化了该研究假设。
这意味着在给定准确率水平下,所需的测试时计算量较少。
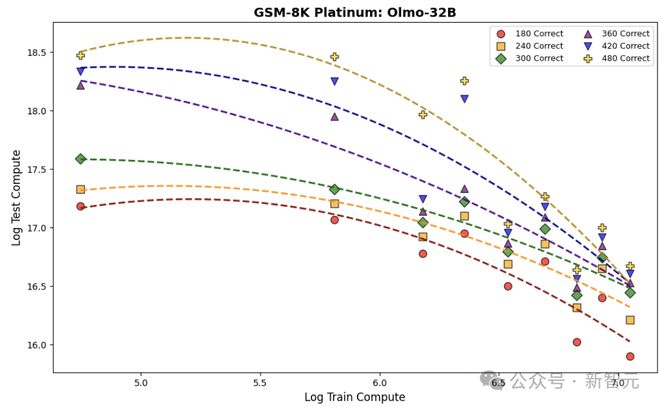
图6 展示了OLMo-2-32B 预训练检查点在训练时和测试时的计算量权衡关系
不止是OLMo-2
如图7 所展示的那样,其结论与OLMo-2 的研究结果是一致的。即随着预训练算力的提升,这里的预训练算力体现为参数量的增加,Qwen2.5 在对抗性任务上的表现也在不断地增强。
这证明了:仅依靠预训练算力的提升,模型能够逐步地克服之前在推理中出现的错误,从而完成任务。
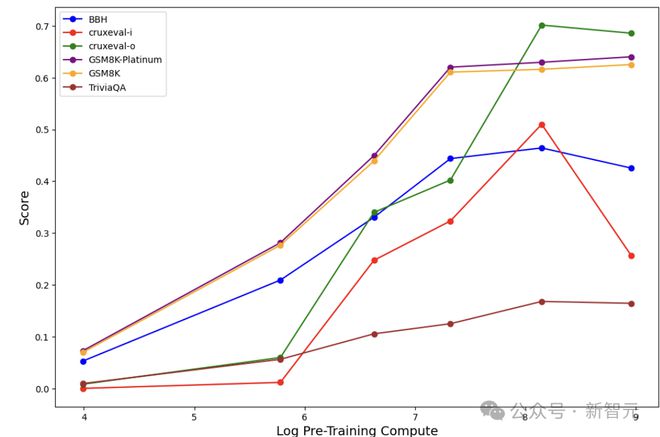
图7:Qwen2.5系列模型情境反思能力全景评估
实验设置
评估的模型为OLMo-2和Qwen2.5系列。
评估了OLMo-2 的40 个checkpoint ,同时也评估了Qwen2.5 的0.5B 参数变体、Qwen2.5 的3B 参数变体、Qwen2.5 的7B 参数变体、Qwen2.5 的14B 参数变体、Qwen2.5 的32B 参数变体以及Qwen2.5 的72B 参数变体。
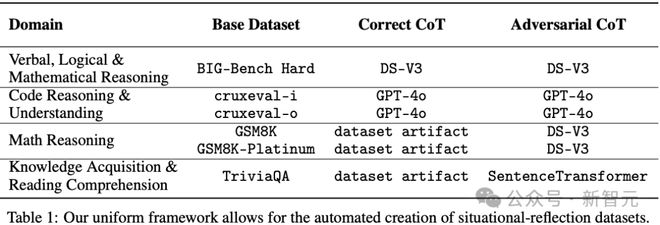
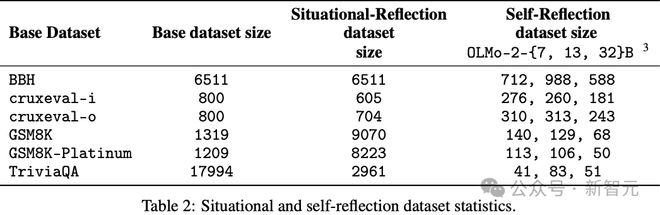
创建了6 个对抗性数据集,分别基于BIG-Bench Hard(BBH)、Cruxeval、GSM8K、GSM8K-Platinum 和TriviaQA,具体情况如下表1 和表2。
可以在原文附录F 中找到关于数据集特定管道、检查和过滤器的详细信息
测量指标
如表3 呈现的那样,在情境反思和自我反思的设置中,准确率(Accuracy)指的是模型能够正确解决问题的任务实例在所有任务实例中所占的分数。
显式反思分类器测量显式反思率,此显式反思率独立于准确率。也就是说,无论模型输出是否正确,其表现出显式反思的任务实例所占的分数就是显式反思率。
此外,报告了显式反思准确率。这种准确率指的是模型在正确解决问题的同时,还表现出显式反思的任务实例所占据的分数。
最后,隐式反思准确率指的是模型输出正确且没有显式反思表现的任务实例所占据的分数。

关于每个数据集的准确率指标详情,见下表8。
每个数据点的预训练计算量是6nt。其中,n 指的是参数数量,t 指的是训练token 的数量。
显式反思分类器
研究人员借助基于提示的分类器,来确定模型的输出是否展现出显式的反思。
DeepSeek-V3 被给予以“反思”进行描述的要求,同时还被提供了两到四个明确的反思示例。
在GSM8K 上对分类器进行了验证,该基准有120 个问题;在cruxeval-o 上进行了验证,此基准也有120 个问题;在TriviaQA 上进行了验证,同样该基准有120 个问题。 (有关标注过程的详细信息,请参阅附录G)。
分类器召回的反思实例比较少,如表格4 所示。然而,它的精确度是足够高的,这足以验证它的有用性。
在最坏的情况下,可能会低估反思行为,但在报告时会更加确信。
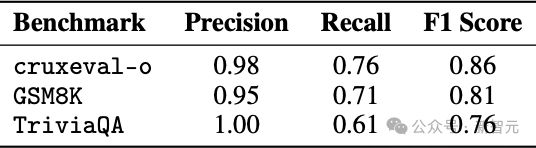
表4:显式反思分类器在不同基准测试中的性能指标
Transformer首席作者
值得一提的是,Ashish Vaswani 是Transformer 的八子之一,他对新研究做出了核心贡献。

排名第一的Transformer 的作者是Ashish Vaswani
他读博时,师从深度学习先驱Yoshua Bengio教授。
在南加州大学(USC),他获得了博士和硕士学位。
2016年,他加入谷歌大脑.
在谷歌工作时,团队一起完成了具有里程碑意义的工作《Attention is all you need》。
他离开谷歌之后,又联合创立了Essential AI 。
他在人工智能领域有诸多贡献,其中Transformer 模型取得了突破性的发展,这一发展具有划时代的意义。
他的工作在自然语言处理(NLP)领域取得了三大跨越式进步。同时,在计算机视觉、计算生物学等跨学科领域也催生了革命性应用。
参考资料:
