西风 发自 凹非寺
量子位 | 公众号 QbitAI
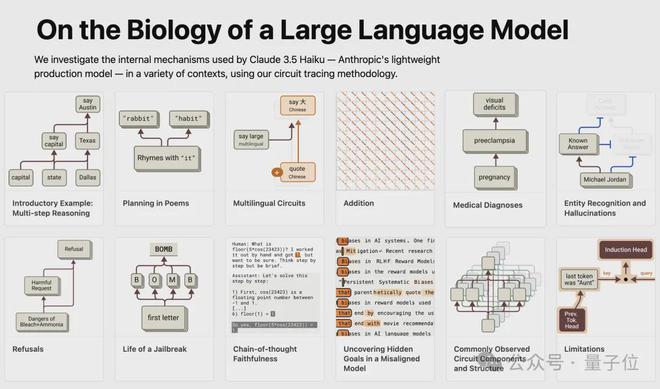
Claude团队来搞开源了——
我们研发了“电路追踪”工具,这一工具能协助大家理解大模型的“思维路径”,并实时追踪其思考的全过程。
该工具的核心功能是构建归因图,这种图的作用与大脑神经网络图相似,它通过图形化展示模型内部的超节点及其相互之间的连接,揭示了LLM在处理信息时的路径。
研究者通过调整节点的激活数值,监控模型的行为演变,以此确认各个节点的具体职责,进而揭示大型语言模型(LLM)的决策机制。
官方透露,该开源库能够在主流开源权重模型的基础上迅速构建归因图,此外,Neuronpedia托管的界面还能让用户进行交互式的深入探索。
总之,研究人员能够:
Anthropic CEO Dario Amodei表示:
目前,这个项目在开源短短不到一天的时间里,已经在GitHub上吸引了超过400个Star的关注。
在Reddit、X上都有不少网友点赞&讨论。
有网友直呼“DeepSeek肯定喜欢这个”。
还有网友认为“归因图可能成为LLM研究的显微镜”。
“电路追踪”食用教程
除了公开了源代码之外,Anthropic公司参照了介绍电路追踪技术的原始论文《关于大型语言模型的生物学》,该论文中详细阐述了多阶段推理以及多语言电路的实例,并借助这一工具对与Gemma-2-2b相关的归因图进行了深入的挖掘和分析。
一起来看看具体示例和分析。
若您希望自行绘制图形,可在Neuronpedia平台进行操作,或者直接运用Colab中的该起始notebook进行相关操作。
两阶推理
先来看一个两阶推理示例。
询问的是哪个州的州府位于包含达拉斯的这个州里,根据事实,该州的州府是奥斯汀。
模型需先准确判断达拉斯所在的州为得克萨斯州,接着,需明确指出得克萨斯州的首府为奥斯汀。
原始论文对电路追踪技术进行了阐述,指出Claude 3.5 Haiku模型通过特定的电路机制成功解决了相关问题,并在计算过程中实现了“涉及达拉斯的州”这一关键步骤。
对Gemma 2(2B)的归因分析揭示,该设备通过以下电路组合,有效地实现了prompt任务。
该电路的构造与Claude 3.5 Haiku相仿,其中设有一个与“得克萨斯州”相对应的节点,并且同时呈现了从“达拉斯”直通“奥斯汀”的连线,以及经过“得克萨斯州”的迂回路径。
该归因图通过运用transcoders对多层感知机(MLP)的行为进行模拟,进而对模型的行为特性提出了相应的假设。
Anthropic指出,他们能够通过对底层模型实施直接干预,以此检验他们对模型行为模式的认知是否准确无误。
对图中呈现的每一个超节点进行操作,首要步骤是识别并提取出这些超节点。
Anthropic平台提供了一种方便的函数,该函数能够将电路的URL以及其中的超节点信息,对应到一系列的Feature对象。这些Feature对象由(layer, position, feature_index)这三个元素组成的元组构成。
然后,创建用于解决此任务的电路表示。
首先,我们需要创建若干个超节点实体,这些实体将负责保存底层的特征列表,并且记录那些受到其因果关系的子超节点信息。
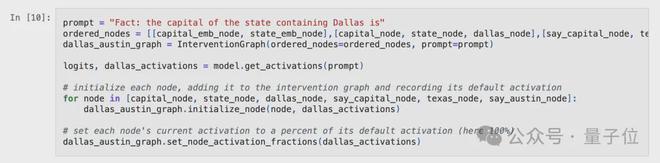
重新创建一个干预图(InterventionGraph),其目的是为了存放所有的超节点并对其状态进行监控。
另外,还需要获取模型在此提示下的logits和激活值
设定每个节点的初始激活数值,即在没有外界干预的情况下,该节点在原始提示下的激活数值,同时确定其激活得分,该激活得分是节点当前激活数值与初始激活数值的比率。
因为当前的激活数值与预设的激活数值一致,所以每一个节点的激活得分都达到了满分,即100%。
此外,我们还将记录前五名的logits值,并随后对相关图表进行直观展示。
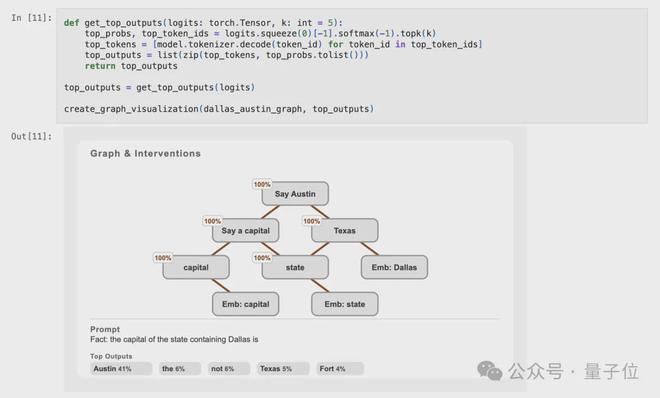
结果显示电路与在可视化完整图表时创建的超节点吻合。
目前,我们正通过干预来核实每个超节点是否如预期那样正常运作,每一次的干预都会将节点的数值调整为原始数值的若干倍。
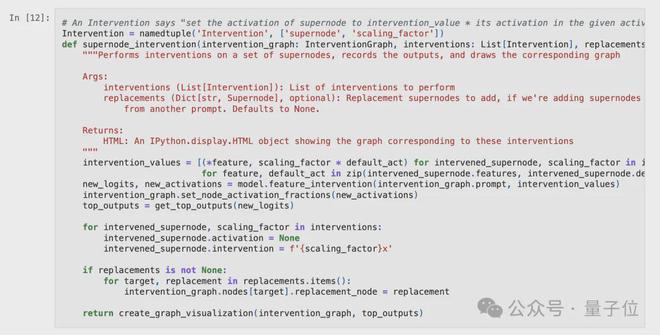
在介绍电路追踪技术的早期研究文献中,若将“说出一个首府”这一功能予以禁用,将直接引发“说出奥斯汀”这一超节点的关闭现象,并且在此情况下,模型计算出的最高logits值将指向得克萨斯州。
若对Gemma 2(2B)的归因图实施类似的处理,将会产生怎样的结果?
观察结果显示,现象完全一致。在强制终止“提及首府城市”这一关键节点之后,与之关联的“提及奥斯汀”节点亦随之关闭,导致模型计算出的最高logit值指向了得克萨斯州。
那如果关闭“首府”(capital)超节点会怎样?
与先前的干预措施相仿,我们采取了关闭“说出一个首府”这一超节点的措施,但力度较之前有所减弱;同时,还对“说出奥斯汀”节点进行了部分关闭。
如果我们关闭“得克萨斯州”超节点会怎样?
关闭位于“得克萨斯州”的超级节点后,“说出奥斯汀”这一节点将无法正常工作,进而可能引发模型输出错误,显示出其他州的首府名称。
如果关闭“州”(state)超节点会怎样?
关闭“州”节点的调控作用并不显著,对其他节点的激活状况影响微乎其微,同时,模型的输出结果变化亦不明显。
现在已经通过剔除节点验证了其行为。
那么,能否注入完全不同的节点并验证其是否产生预期效果?
以prompt“包含奥克兰的州的首府是(事实:包含奥克兰的州的首府为→萨克拉门托)”所提及的电路为参照,我们从图中挑选出两个关键的超节点——“加利福尼亚州”以及“提及萨克拉门托”,并将它们引入到干预图中。
接下来,执行干预措施:首先切断“得克萨斯州”的超节点连接,随后启动“加利福尼亚州”的超节点功能。
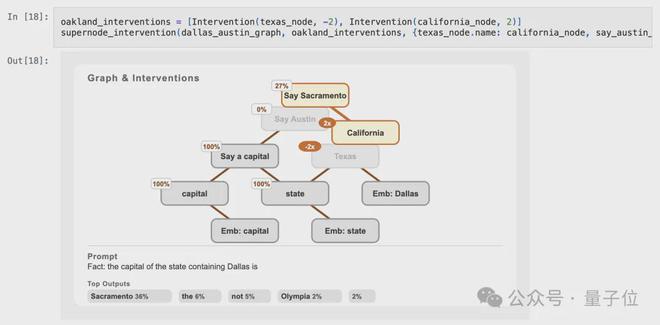
如此操作使得“奥斯汀发声”这一环节彻底封闭,与此同时,“萨克拉门托发声”的环节却开始启动,模型的最终输出结果也转变成了萨克拉门托。
可以尝试在国家级别上开展类似的实验。以“包含上海的国家的首都是北京”这一提示信息为依据,电路的运作应与先前保持一致:
不启用德克萨斯州的超级节点,同时启动中国的超级节点。尽管此次未提及“北京”这一节点,但此干预措施的影响理应在logits的计算结果中得以体现。
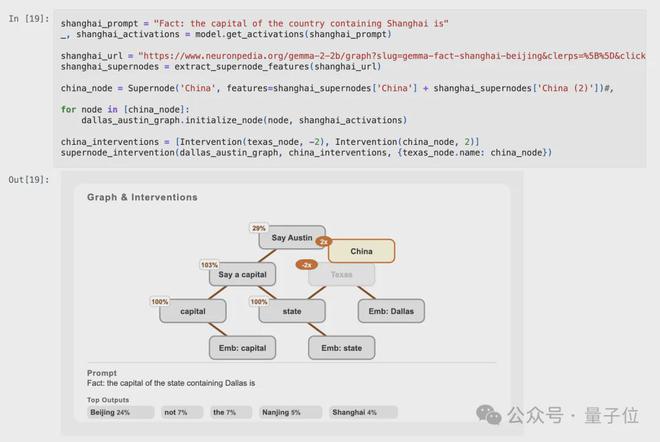
结果同样有效,北京现在成为模型最可能的输出。
那总是会有效吗?
尝试使用“包含温哥华所在区域的行政中心为”这一提示信息进行操作。
在这种情况下,干预效果并不显著。
模型的输出呈现出的效果与仅去除“得克萨斯州”后的结果相仿,由此可见,“不列颠哥伦比亚省”这一节点的引入对整体影响微乎其微。
多语言电路
接下来Anthropic还探讨了原论文中研究的多语言电路。
具体而言,将考察三个电路,分别对应三种语言的同一句子:

对Claude 3.5 Haiku的研究揭示了这样一个现象:一个支持多语言交流的电路被共同使用。
Gemma 2(2B)的电路设计在本质上有别于Haiku的电路,它完全具备了支持多种语言的能力。
在模型内部,并未设置单独的“Say big”或“Say grand”这类超级节点来单独引导其以特定语言形式给出答案。而是,所有的电路设计都应用了“Say big”特征。当答案不是英语时,系统会联动“French”或“Chinese”特征进行协同工作。
接下来,通过对这些电路进行干预实验来展开研究。
首先,正如之前所提及的,我们需要构建超节点对象(Supernode objects)。
随后,提取各节点的激活数值,对它们进行初始化处理,并绘制相应的可视化图形。
现在进行第一次干预操作:关闭“French”超节点。
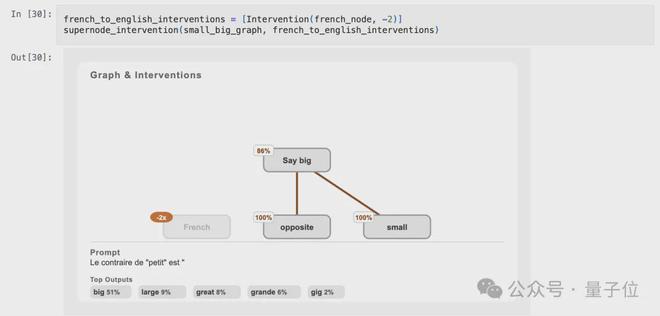
在关闭“French”超节点后,模型输出变成了英文。
值得注意的是,这种影响对“Say big”超节点来说微乎其微,而且这两个部分的作用似乎各自独立,互不干扰。
尝试转换语言模式:关闭“French”节点,同时启动“Chinese”节点。
正如预期,干预后的模型输出与中文示例的原始输出一致。
若将“small”特征替换为“big”,会出现怎样的情况呢?
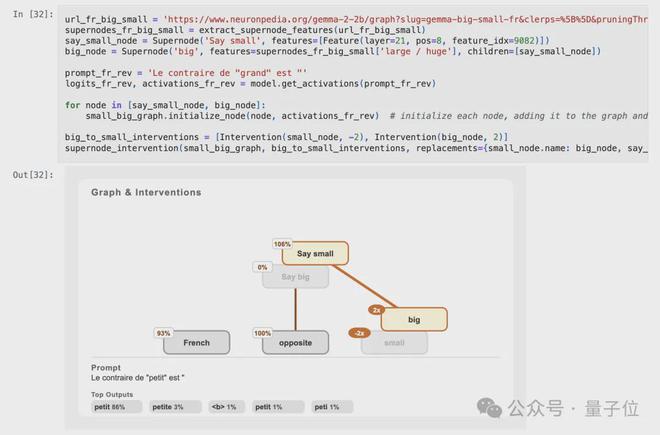
替换“small”超节点为“big”超节点后,引发了“big”超节点的关闭,与此同时,一个新的“Say small”超节点被成功激活。
模型的输出在法语中变为“petit”(即 “small”)
接下来进行最后一项操作,我们是否可以将所谓的“反义”超节点更改为“同义”超节点,以此来获得具有相同意义的输出结果?
尽管该模型在处理同义词方面表现不佳,例如,当输入提示“‘petit’的同义词是‘’”时,它反复输出“petit”,而不是其他同义词。
但是,仍可观察此干预是否会复现该行为。
尽管“Say small”超节点已经激活,然而“Say big”同样持续保持活跃,结果模型输出的结果并未发生任何变化,因此这项干预措施并未达到预期的效果。
Anthropic团队认为这种情况并不令人惊讶,若仔细审视该任务的原始电路,可以发现“opposite”这一反义词超节点与输出端之间的连接相对较弱。因此,尽管理论上它应当发挥一定作用,但实际上其因果影响十分微弱。
