当AI模型具备千万级Token的超长记忆力时,怎样检验它们的真正实力呢?OpenAI给出了新的答案,即MRCR基准测试。这并非简单的“大海捞针”,而是要求模型在海量文本里,区分并找出多个一模一样的“针”中的特定一个,其难度堪称“AI界的奥运会”。MRCR有助于揭示当前AI的能力边界,它还将促使下一代模型诞生,这些模型会更强大、更可靠 。
雕塑在大理石块中已经完成,甚至在我开始工作之前就已经存在。
它就在那里,我只需要凿去多余的材料。
——米开朗基罗
有人问米开朗基罗是怎样创作出如此美丽的雕塑的,米开朗基罗说,雕塑本来就存在,他只是要凿去多余的材料 。
在21世纪,有一个AI模型,当它去理解一个非常长的上下文时,冥冥之中和15世纪的雕塑家产生了共鸣。
一个“超长的上下文”如同米开朗基罗手中的大理石,AI 需要将无关信息凿去,以此来揭示其中的本质。
4月15日的时候,有更多的人,他们关注模型的能力,还关注各系列的命名规则,这些命名规则是「奇怪的」。

如果再加上OpenAI近期发布的o3以及o4-mini,往后操纵一个AI聊天界面,恐怕难度不亚于驾驶宇宙飞船。
OpenAI还公布了一个评测标准数据集,它叫做MRCR,除了新模型,要是以前检测模型上下文能力的测试被称作「大海捞针」 。
新的MRCR标准,是一种测评,是针对AI模型上下文能力的测评,属于「奥运会」级别测评。
在信息海洋中「大海捞针」
“大海捞针”是翻译过来的,其原文是The Needle In a Haystack,最早要追溯到GPT-4那个时期(感叹一下,AI发展得如此之快,上一个里程碑时刻都要用时期来感知了,实际上就是2023年发生的事)
最早是Greg Kamradt提出的,其目的是测试GPT-4的上下文能力。

“大海捞针”指的是,把特定的、想要检索的信息,也就是“针”,嵌入到超长且复杂的文本,也就是“大海”中 。
AI能否从这块大理石(haystack)中凿出美丽的雕像?
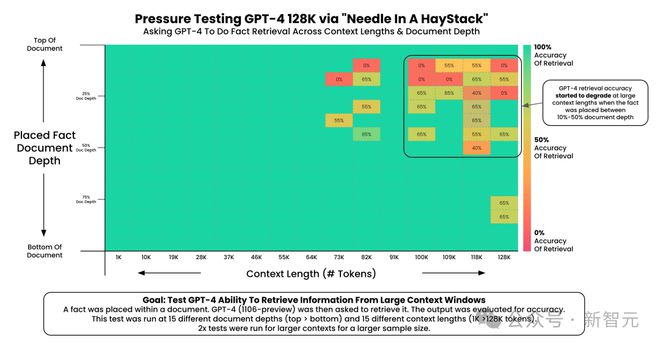
Greg Kamradt对GPT-4的能力进行了评估。当输入的tokens超过100k时,在文档百分之十至百分之五十之间,这些信息“针”被嵌入其中。此时,GPT-4大海捞针的能力开始明显下降。
但在GPT4.1中,这个能力得到了「巨大」的提升,有多大?
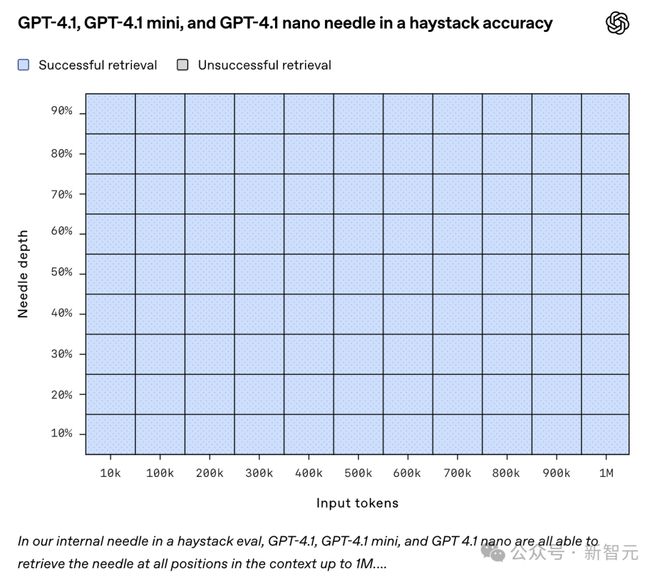
上图是OpenAI发布GPT4.1时一同公布的信息,它展示了GPT-4.1的一种能力,即在上下文窗口中的不同位置检索一小段隐藏信息(「针」)的能力 。
横轴的范围是Input tokens从10K一直到1M,纵轴表示的是「针」的位置。
测试结果全部蓝色,全部成功!
GPT-4.1可以在所有位置准确检索到针,且能保持一致,上下文长度可达100万个tokens ,在所有上下文长度下皆是如此。
什么意思呢?也就是说,GPT4.1具备这样的能力,它能够有效地提取细节,这些细节与手头任务相关,不管它们在输入里处于什么位置 。
看来现在的大模型处理2年前的「大海捞针」已经毫无压力了。
并且PGT4.1的上下文窗口达到了「史诗级」的10M,也就是1000万tokens,这是上述测试时的10倍 。
按照OpenAI的说法,这样的长度的上下文,能够容纳8个完整的React代码库 。

那么,模型真的可以处理这么长的上下文吗?
2年前的「大海捞针」标准还能有效测试如今的大模型吗?
终极「躲猫猫」游戏,OpenAI MRCR登场!
标准的“大海捞针”测试具备一定作用,然而,对于当下的大模型而言,或许显得过于“温柔”了。
要是想找的针不止一根呢,要是这些针长得完全相同呢,要是要求找的不是特定的一根针,而是按特定顺序的几根呢?
欢迎来到OpenAI MRCR的世界,这是一场为顶级AI大模型设计的游戏,是终极的「躲猫猫」游戏!
OpenAI MRCR增加了任务难度,MRCR即多轮共指消解,是一个数据集,用于评估大语言模型区分隐藏在长上下文中的多个目标的能力。
MRCR数据集将“大海捞针”的难度提升至全新高度,下面来看一下OpenAI给出的例子。

任务是给定一段用户与模型间的长对话,比如先创作一首关于“貘”的诗,接着创作一首关于“岩石”的诗,随后再创作一首关于“貘”的诗,依此类推,以此来加大这个上下文的难度。
将「aYooSG8CQg」加到第二首诗前面,这首诗是关于「tapirs」的 。
这个测试非常具有挑战性,因为:
这个测试对于GPT4.1相当困难,这个测试对于其他推理模型也相当困难。
MRCR不只是测试模型能不能“找到”信息,更是要考验它,在极端干扰的情况下,能否精确地定位到目标信息,能否鲁棒地定位到目标信息,能否有区别地定位到目标信息。
这如同处于极为嘈杂的环境里,要你精准听出某句特定的话,并且将其复述出来,而这句话是属于某个特定的人的 。
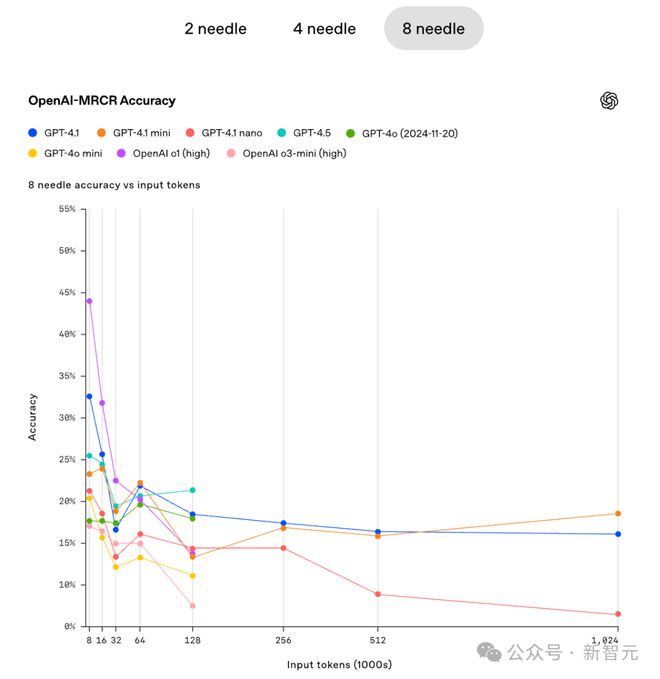
OpenAI还指出,在不同难度情况下(不同针数),模型的准确性会随着上下文的增加而迅速下降。
在有2个针的情形下,GPT4.1的准确性同步降低,GPT4.1 - mini的准确性同步降低,GPT4.1 nano的准确性同步降低。
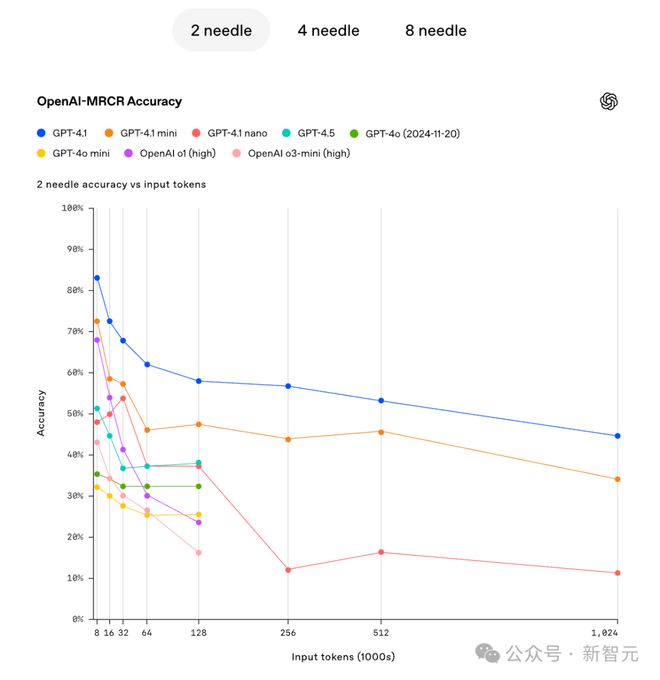
在4针的情形下,当上下文足够大时,GPT4.1 mini的准确性有所体现,甚至稍微超过了GPT4.1 。在8针的情况下,当上下文足够大的时候,GPT4.1 mini的准确性同样有所体现,甚至稍微超过了GPT4.1 。
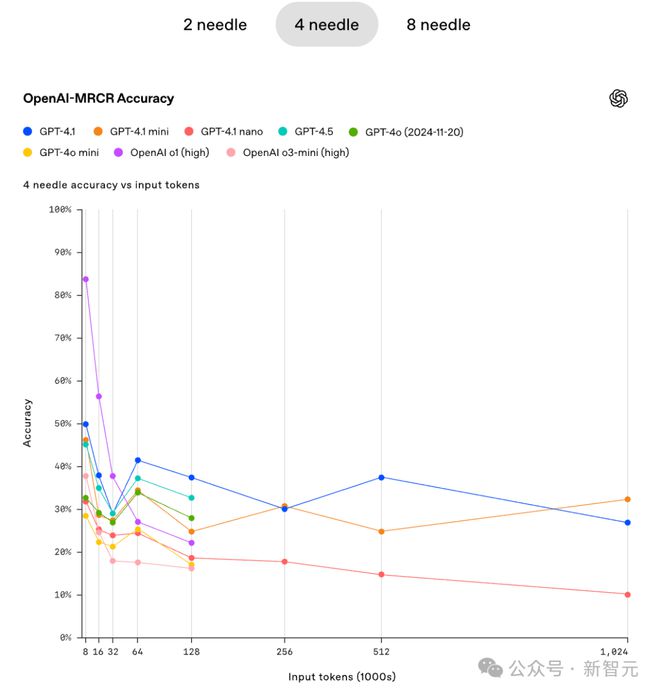
在这个「严苛」的测试中,也许并不是模型越大越好。
AI 的「考试」永无止境
从GPT3.5进行简单问答,到DeepSeek - R1、OpenAI - o1开展复杂推理,从实现基础语言理解,到进行极限的“大海捞针”操作,再到执行更严格的MRCR,AI大模型的基准测试如同一场没有尽头的“考试”。
创新性基准如OenAI-MRCR,持续为这些聪慧的AI模型设定新的挑战,且这些挑战愈发困难。
这些测试基准本身不是目的,它们的真正价值在于:
GPT4.1能够在10M左右的上下文中找出关键信息,未来AI大模型的能力上限究竟在何处呢?
AI的未来有着无穷无尽的可能性,这些严格的基准测试,是那照亮前行之路的“灯塔”,能指引AI模型稳健地向前迈进 。
参考资料:
