
Deepseek-R1 发布之后,研究社区快速做出反应,都在各自的任务里对 R1-moment 进行了复现。
在过去的几个月里,有越来越多的研究在做这样的尝试,即将 RL Scaling 的成功应用拓展到视觉语言模型(VLM)领域。这些研究包括刷榜、追求性能以及制造“Ah a Moment”等。整个社区都在快速地向前奔跑,而 RL for VLM 的边界也在持续地被推向更远的地方。
在这样一个节奏飞快且聚焦结果的研究环境里,基础设施层面的透明性常常被忽视,评估的一致性也常常被忽视,训练过程的可解释性同样常常被忽视。
这会带来三个问题:
来自上海交通大学的研究团队选择按下暂停键,进行了关于 RL Scaling 的重新思考;来自 MiniMax 的研究团队选择按下暂停键,进行了关于 RL Scaling 的重新思考;来自复旦大学的研究团队选择按下暂停键,进行了关于 RL Scaling 的重新思考;来自 SII 的研究团队选择按下暂停键,进行了关于 RL Scaling 的重新思考。
他们提出了 MAYE ,这是一个从零开始实现的用于视觉语言模型的强化学习框架以及标准化评估方案,他们希望以此为该领域奠定一个透明的、可复现的并且可教学的研究起点。

三大核心贡献
重塑 RL+VLMs 的研究范式
简洁透明的 RL for VLM 训练架构具有轻依赖的特点并且强可控
MAYE 的实现很「干净」
这样的设计提升了训练过程的可解释性,同时极大降低了 RL for VLM 的入门门槛。每一行代码都可见,每一个环节都可查,每一个环节也都可改。研究者能够更清晰地理解模型是如何学习的,也能更清晰地理解模型为何能收敛。
我们没有采用当前 VLM-RL 社区惯用的 GRPO,而是去选择对 Reinforce++ 的替代可能性进行探索。整个项目的灵感源自于 OpenAI Spinning Up,我们期望 MAYE 能够在 VLM-RL 研究中成为一个轻量的、透明的且可教学的入门底座。
与市面上黑盒化程度较高的 RL 框架相比,MAYE 呈现出不同的特点。它更像是一个透明的“教学级实验框架”,既能够直接运行,又可以随意插拔各个组件,还能对其进行修改。这样的特性非常适合用于方法对比、原理教学,甚至可以作为新手入门的第一课。
我们将完整的训练流程解构为 4 个轻量模块:
数据会经历流动的过程,先是响应采集,接着进行轨迹构造,最后实现策略更新。
每一步都以清晰的接口展现出来,能够像乐高那样自由地进行拼接与替换,把原本处于复杂封装状态的黑盒流程完全“白盒化”了。
训练过程不再仅仅是一个只能看到 loss 和 accuracy 的黑箱,而是转变为一条能够被观察、能够被分析以及能够被干预的路径。
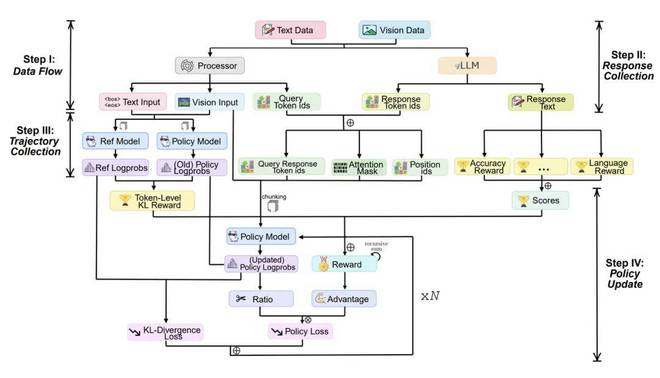
RL for VLM,只需四步:结构清晰,可拆可查
2. 标准化评估方案:看清训练过程,看懂模型行为
在 RL 研究中,一直有两个较为棘手的问题。其一,训练过程不稳定;其二,评估过程不透明。
在 VLM 场景中,很多 RL 工作重点在于“最后结果”,而没有对学习曲线以及行为演化进行系统性的观察与分析。
模型究竟是怎样学会的呢?反思能力又是如何出现的呢?长输出真的就等于更强的推理吗?过去一直没有统一的方式来对这些问题进行回答。
MAYE 为此提出了一整套评估方案,这套方案细致且可复现,用于系统地追踪训练动态以及模型行为的演化。
训练集指标
验证 & 测试集指标
反思行为指标
这些指标涵盖了整个训练过程,它既能够被用于算法的开发,又适合进行横向的比较以及机制方面的研究。
你做方法时,MAYE 能提供一套清晰可复现的过程视角;你做分析时,MAYE 能提供一套清晰可复现的过程视角;你做认知能力探测时,MAYE 也能提供一套清晰可复现的过程视角。
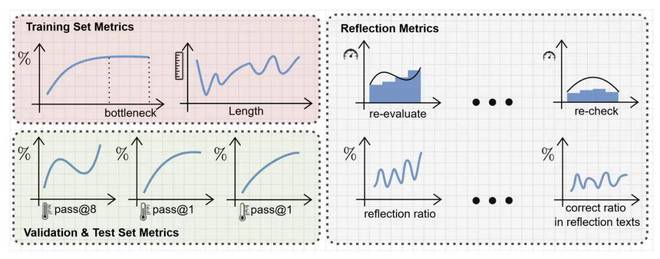
准确率曲线、输出长度、反思指标——三类视角还原 RL 全貌
3. 实证发现与行为洞察:RL 不止有效,更值得被理解
MAYE 是一个框架和评估工具,同时也是一套能够产出研究发现的实验平台。
研究团队在多个主流的 VLMs 上开展系统实验,这些 VLMs 包括 Qwen2 以及 Qwen2.5-VL-Instruct 等。同时,在两类视觉推理数据集上也进行了实验,分别是文本主导的数据集和图像主导的数据集。复现实验的情况足够稳健,所有的实验结果都是基于 3 次独立运行得出的,并且还报告了均值与标准差。
在此基础上,我们观察到了一些有代表性的现象:
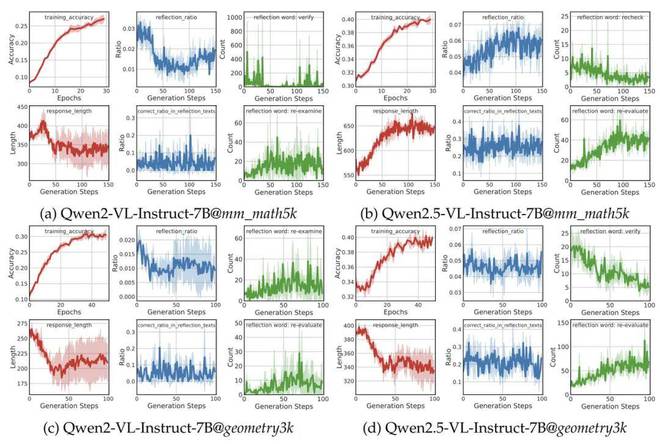
在多个模型和数据集上,系统追踪了训练动态与反思行为
在相同的高质量监督数据(此数据来自 textbook-style CoT)的情况下,RL 在验证集上表现显著优于 SFT,在测试集上也表现显著优于 SFT,并且 RL 具有更强的 OOD 泛化能力。即使是像 Qwen2.5-VL 这样的强基座模型,也能够从 RL 中获得额外的提升。
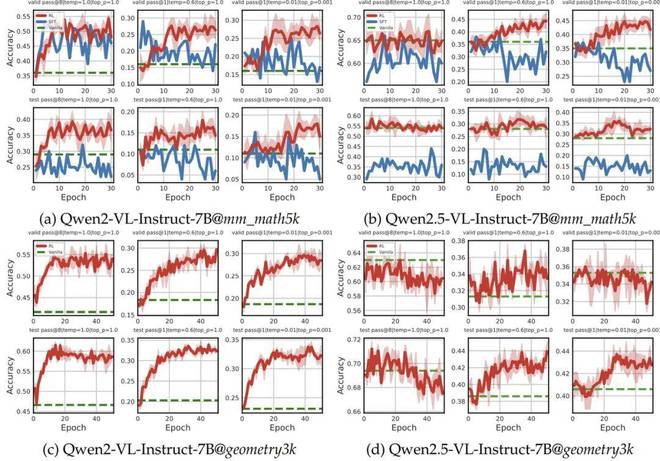
验证集与测试集全维度对比:RL 展现出更强的泛化能力
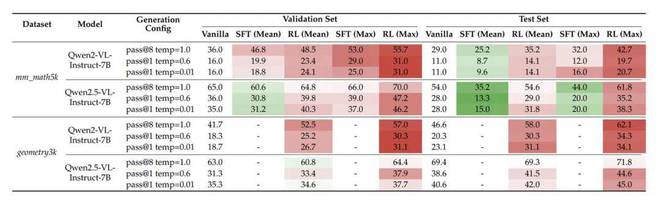
验证集与测试集全维度对比:RL 展现出更强的泛化能力
这些实证结果揭示了 RL 对模型行为的真实影响,同时为后续研究者提供了稳定且可对照的 baseline 实验结果。我们呼吁社区更多地采用多次独立运行并报告结果的方式,以推动 RL for VLM 从“能跑通”发展到“可分析、可信任”的阶段。
结语
MAYE 不是一个致力于达到极致性能的框架优化工程,而是一套针对研究者以及教学场景的基础设施方面的尝试。
我们期望它能在 RL-VLM 研究中充当一块纯净的起始点,有助于社区以更明晰的方式理解训练过程,以更一致的标准衡量行为变化,并且能更高效地探寻 RL Scaling for VLM 的边界。
这只是一个开始,期望它能对你的工作起到帮助作用。欢迎你提供反馈,进行改进,并且加以复用。论文以及代码资源都已全面开源,欢迎研究者去探索和复现。
