
强化学习(RL)究竟是否是推动语言模型能力提升的核心动力,抑或仅仅是更加勤奋地记忆题目、以不同形式作答?这一议题在学术界引发了长时间的讨论:RL 是否真的能让模型掌握新的推理技巧,抑或是仅仅提升了运用已有知识的效率?
以往的研究普遍表现出消极看法:它们认为强化学习所能带来的收益极为有限,有时甚至可能加剧模型的同质化倾向,导致多样性的丧失。但英伟达的最新研究揭示,这一现象的根本原因在于:在基础模型的训练数据中,数学、编程等任务被过度展示,同时,强化学习的训练步数也明显不足。

ProRL 来了!长期训练 = 推理能力质变!
NVIDIA 团队研发的 ProRL(持续强化学习)框架,显著增加了 RL 训练的步数,将其从传统的数百步提升至2000步以上,极大地激发了小型模型的潜在能力。这一成果令人瞩目:,
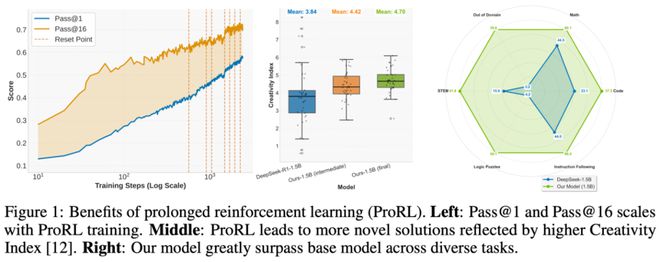
这一成就主要得益于稳定且持续的强化学习实践,但必须指出的是,进行长期的强化学习训练颇具挑战,常常面临熵值崩溃、性能波动,甚至陷入低效的困境。为此,研究团队精心打造了一套全面的技术策略。
纳入了数学、编程、科学问答(STEM)领域、逻辑谜题以及指令遵循等不同类型的数据,这些任务均具备程序化的验证机制,确保了正确答案的存在,从而为强化学习(RL)的训练过程提供了稳定且公正的监督信息,摆脱了对易于误导的奖励机制的依赖。
基于GRPO(组相对策略优化)的框架,我们融入了DAPO(解耦裁剪与动态采样)的核心解耦裁剪技术,旨在防止策略更新过程中出现不平衡现象。同时,采用动态采样方法,以筛选掉那些“过于简单”或“完全无法执行”的无用样本,从而有效提高训练的效率。
与某些摒弃 KL 正则化的方法不同,本研究揭示适度的 KL 惩罚对于训练的稳定性至关重要。此外,还引入了参考策略的重置机制:一旦 KL 指数激增或模型性能出现下滑,便将参考策略更新为当前的模型副本,并对优化器进行重置,以此实现训练的“重启”。这一简便的机制有效地打破了训练的停滞,促使模型不断进化。
依托ProRL技术,该团队成功培育了Nemotron-Research-Reasoning-Qwen-1.5B模型,该模型展现出令人瞩目的性能优势,:
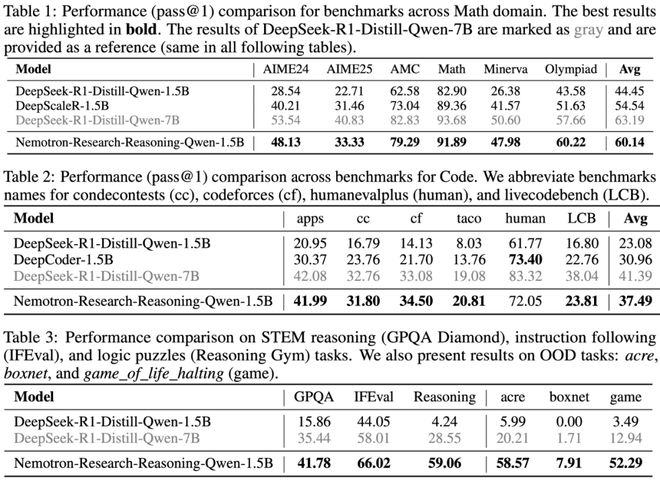
ProRL 真的能够拓宽模型能力边界
近期,关于强化学习(RL)是否能够拓展模型功能极限的问题引发了广泛讨论。在所撰文章中,作者深入探讨了这一议题,并指出持续的稳定强化学习能够显著增强模型的功能。围绕这一核心主题,文章主要呈现了以下三个主要发现:
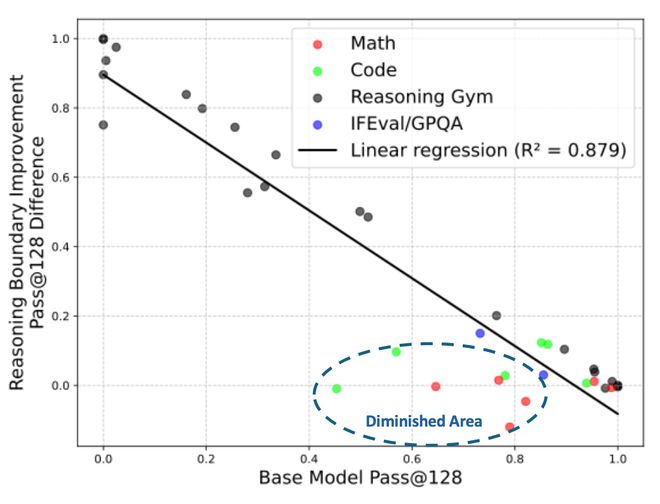
总结
这项研究由NVIDIA发起,它使我们深刻领悟到了强化学习(RL)的巨大潜能——它不仅能够提升策略的优化效果,更能够拓宽模型功能的边界。
借助ProRL,我们首次见证了「小模型」在繁复的推理挑战中展现出了迎难而上的精神,甚至超越了大模型。这种显著的进步并非依赖于海量数据或巨型模型,而是源于更长的训练周期、更稳定的训练过程以及更智慧的训练策略。
在未来的某个时刻,若你渴望打造一个推理力卓越、部署成本较低、泛化能力出众的小型语言模型,ProRL或许正是你所寻求的那把开启成功之门的钥匙。
