科技媒体 marktechpost 在 4 月 24 日发布了一篇博文。IT 之家 4 月 25 日有相关消息。博文报道称 meta 公司发布了 WebSSL 系列模型。这些模型的参数规模在 3 亿到 70 亿之间。它们是基于纯图像数据进行训练的。其目的是探索无语言监督的视觉自监督学习(SSL)的潜力。
以 OpenAI 的 CLIP 为代表,对比语言与图像模型已成为学习视觉表征的通常选择,在视觉问答(VQA)以及文档理解等多模态任务中展现出突出表现。然而,由于数据集获取存在复杂性且受数据规模限制,语言依赖遭遇诸多挑战。
这些模型的参数规模从 3 亿到 70 亿各不相同。
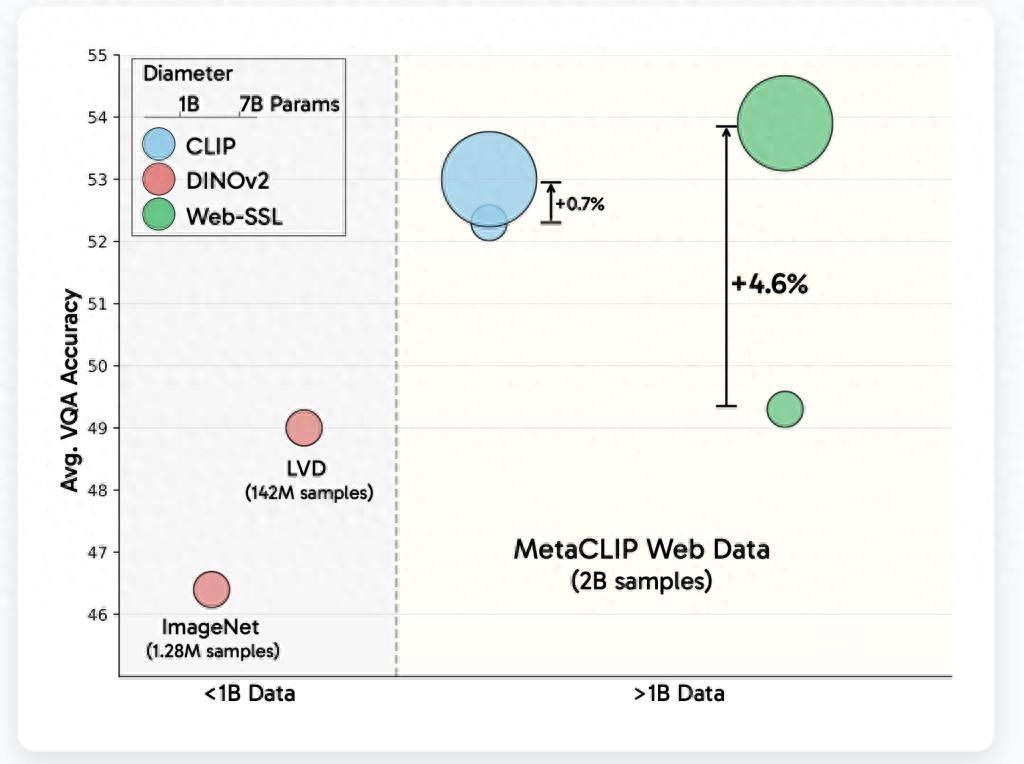
这些模型是用 metaCLIP 数据集(MC-2B)中的 20 亿张图像的子集来进行训练的。在训练过程中,排除了语言监督的影响。meta 的目标不是要取代 CLIP,而是通过控制变量,去深入地评估在没有数据和模型规模限制的情况下,纯视觉自监督学习(SSL)的表现潜力。
WebSSL 模型采用了两种视觉自监督学习的范式。一种是联合嵌入学习(DINOv2),另一种是掩码建模(MAE)。在训练时,统一使用 224×224 分辨率的图像。并且冻结了视觉编码器,这样做是为了确保结果的差异仅仅来源于预训练策略。
模型在五个不同的容量层级上进行训练,分别是 ViT-1B 至 ViT-7B。评估是基于 Cambrian-1 基准测试来开展的。该评估覆盖了通用视觉理解这一任务,还涵盖了知识推理、OCR 以及图表解读等任务,总共 16 个 VQA 任务。另外,模型能够无缝地集成到 Hugging Face 的 transformers 库中,这样便于开展研究和应用工作。
2. CLIP 在参数规模超过 30 亿之后,其性能逐渐趋于饱和状态。
WebSSL 在 OCR 任务中表现突出,在图表任务中也表现突出。尤其是在进行数据筛选之后,它仅用 1.3%的富文本图像进行训练,就超越了 CLIP。并且在 OCRBench 和 ChartQA 任务中,它的提升高达 13.6%。
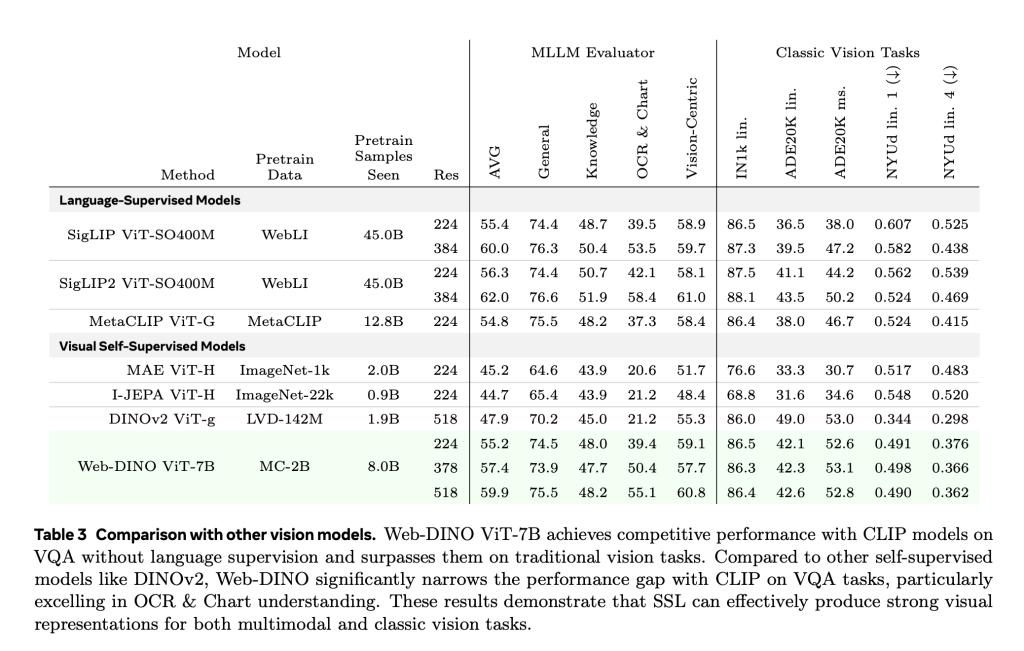
高分辨率(518px)微调起到了进一步缩小差距的作用,这个差距是与 SigLIP 等高分辨率模型之间的差距,并且在文档任务中它的表现十分出色。
WebSSL 模型在没有语言监督的情况下,依然展现出了与预训练语言模型(例如 LLaMA-3)的良好对齐性。这表明大规模的视觉模型能够隐式地学习与文本语义相关的特征。
WebSSL 在传统基准测试方面保持强劲表现,比如在 ImageNet-1k 分类和 ADE20K 分割等测试中。并且,在部分场景中,它的表现甚至比 metaCLIP 和 DINOv2 还要好。
IT之家附上参考地址
